
Qu’est-ce qui se passe quand on tape https://www.google.fr dans notre navigateur ?
Disclaimer
Cet article a été initialement écrit en anglais (conformément à la consigne) mais le blog étant en français, je me suis permis de le traduire ci-dessous :
Introduction
Dans le cadre de ma reconversion en informatique, je dois apprendre à coder, mais aussi à communiquer avec d’autres personnes et, en particulier, à rédiger de la documentation technique. Dans cette optique, nous devons rédiger un article de vulgarisation au sujet du réseau et du fonctionnement d’Internet.
C’est quoi internet ?
Tout d’abord, il faut bien comprendre ce qu’est Internet pour comprendre ce qui va suivre : Internet c’est de l’interconnexion de réseau (c’est dans le nom d’ailleurs : inter-network (ou réseau de réseau dans la langue de Michel Drucker) L’idée fondamentale qui a derrière cette idée, c’est de se dire que chaque point du réseau, chaque ordinateur, est à la fois émetteur et récepteur. Ce qui permet une résilience du réseau et une décentralisation by design.
Maintenant que cette base est posée, revenons à nos moutons électriques et connectons-nous à « https://www.google.fr »
TCP/IP
La première étape, consiste à savoir par quelle magie on va relier notre ordinateur, à la machine sur laquelle est hébergé le site web de google… Et pour réaliser cette prouesse, notre ordinateur va envoyer une requête ; c’est-à-dire un genre de message destiné au serveur de google : « S’il te plaît gentil serveur, montre-moi la page internet que tu abrites s’il te plaît ». Et pour faire ça, il va utiliser le protocole TCP/IP.
Il s’agit de deux protocoles; et si vous êtes un peu malin vous avez deviné qu’il s’agit de TCP et IP !
On confond souvent les deux, car ils vont souvent ensemble, mais c’est bien deux protocoles distincts
TCP
Le protocole TCP, organise les données afin qu’elles puissent être transmises sur le réseau
C’est ce protocole qui établit la connexion entre la source et la destination, et garantit que cette connexion reste active du début à la fin de la communication.
C’est également TCP qui divise les grosses quantités de données en petits morceaux qu’on appelle des paquets.
Pour faire une analogie, au lieu d’envoyer tout un livre d’un coup, c’est comme si on envoyait le livre page par page, en demandant à chaque fois :
« Je viens de t’envoyer la page 53, tu l’as bien reçue ? Oui ? Alors j’envoie la suivante ! Non ? Eh bien, c’est pas grave, je te la renvoie ! »
À l’autre bout de la chaîne, c’est également TCP qui reprend les pages une par une pour reconstituer le livre complet.
On parle alors de recomposition de donnée.
IP
Le protocole IP, lui, permet de définir les adresses de départ et d’arrivée de la requête, et pour chaque paquet, il va trouver un chemin possible (sans garantir que tous les paquets suivent le même chemin)
Trouver un chemin
Il faut imaginer que chaque paquet a une petite étiquette avec l’adresse de destination et l’adresse de départ. Et à chaque routeur croisé sur le chemin regarde l’adresse de destination. Le routeur ne connaît pas forcément l’adresse finale, mais il connaît ses voisins et sait dans quelle direction il doit envoyer le paquet pour se rapprocher de la destination. Il renvoie donc le paquet à un autre routeur, qui fait la même chose, et ainsi de suite, jusqu’à ce que le paquet atteigne le bon serveur.
En revanche, c’est TCP qui est chargé du suivi des paquets, de la vérification, et de la remise en ordre des paquets.
C’est pourquoi ces deux technologies sont utilisées ensemble dans ce qu’on appelle TCP/IP car elles vont de pair, et comme j’expliquais plus tôt : on en arrive à confondre parfois qui fait quoi.
Les numéros gagnants
Maintenant qu’on sait ça, on pense que le plus dur est fait et qu’on peut envoyer nos paquets à la bonne adresse… Et ben non !
En effet, les humains parlent avec des noms. Exemple google.fr, wikipedia.org ou blog.nanuq.me
Mais les machines elles… elles parlent avec des numéros ! Respectivement ça correspondrait en IPv4 aux numéros suivants pour les exemples ci-dessus :
- 142.250.201.163
- 141.94.212.184
- 46.231.240.132
et en IPv6 pour les numéros suivants :
- 2a00:1450:400e:805::2003
- 2a02\:ec80:600\:ed1a::1
- 2a0c\:e303:0:8400\:aaf5:6906:834d\:a605
Or, le protocole IP qui trouve le chemin entre le point de départ, et le point d’arrivée a justement besoin de ces numéros !
Et avant d’aller plus loin, vous vous demandez sûrement pourquoi il y a deux numéros différents ?
IPv4 & IPv6
C’est pas vraiment le but de l’article mais pour faire court… Dans des temps immémoriaux : au début de l’émergence d’internet fin des années 80, début des années 90, le monde découvre la version 4 de IP qui ne devait servir qu’à faire des tests à l’échelle mondiale chez les gros acteurs du moment comme IBM, les universités, ou les agences gouvernementales. (Les versions précédentes de IP étaient expérimentales et n’ont été utilisées en laboratoire dans les départements de R&D et à très petite échelle.) Au départ, personne ne pensait que cette technologie dépasserait ce cercle restreint. Mais ça fonctionnait bien, et Internet a commencé à se populariser à partir des années 90 et ce prototype qui ne devait être que temporaire pour une phase de test est devenu la norme.
Or, IPv4 un système d’adresse en 4 blocs de chiffres allant de 0 à 255. Il y a quelques adresses réservées et quelques exceptions mais en gros ça représente donc 4 milliards d’adresses différentes. Et ce nombre n’est pas extensible. Il y a un nombre fini d’adresses, mais le nombre d’utilisateurs augmente, ainsi que le nombre de machines, et il fallait plus d’adresses !
C’est pourquoi a été créé IPv6 qui lui, propose des adresses écrites sur 8 blocs en hexadécimal comme par exemple : 2a0c:e303:0:8400:aaf5:6906:834d:a605
Et le nombre possible d’adresses avec ce système est gigantesque ! On dit que ce nombre est tellement grand qu’on dit souvent qu’il dépasse le nombre d’atomes dans l’univers observable. Autant dire qu’on est tranquilles pour un moment.
Et pour les petits malins du fond de la salle qui se demandent « Et IPv5 ? On passe de 4 à 6 ? » Et oui ! IPv5 est lui aussi expérimental et n’a servi qu’à faire des tests théoriques dans les laboratoires de R&D
Vous me direz que ce petit cours d’histoire était vachement sympathique, mais on fait quoi avec de nos adresses et de nos numéros ?
C’est là que le DNS intervient !
DNS
DNS pour Domain Name Server est une technique qui permet de faire le lien entre les noms et les numéros.
Imaginez un monde où les noms de domaine n’existeraient pas et qu’il faudrait se souvenir de tous les numéros… Pas pratique hein ?
Le DNS un peu à la manière d’un agenda de téléphone, indiquera pour chaque nom de chaque site, son numéro d’adresse IP.
On trouve souvent sur internet cette explication : que les DNS ont été inventés uniquement pour faciliter la vie aux humains qui préfèrent des noms uniques et mémorisables comme « mon-super-site.bidule » plutôt que « 195.042.217.12 ». C’est en partie vrai.
L’autre explication c’est que ces noms permettent une stabilité par rapport aux adresses IP. En effet, les adresses IP sont distribuées par les fournisseurs, et elles peuvent changer.
Pour faire une analogie, je sais que Bob habite au 42 Ada Lovelace Street à Genève, mais s’il déménage, je dois connaître sa nouvelle adresse postale.
Mais dans les faits, je m’en fiche de savoir où il habite, moi je veux juste voir mon ami Bob !
De la même façon, utiliser un nom de domaine avec un système de DNS permet de (presque) toujours vous rediriger vers la bonne adresse de serveur (sans que vous n’ayez rien à faire car tout ça se passe dans votre dos) même quand la machine ou le fournisseur d’accès change (et par conséquent les adresses IP).
Il suffit d’une requête qui demande gentiment « Où se trouve l’adresse de ‘mon-super-site.fr’ s’il te plaît ? » et le DNS nous répond !
C’est quand même plus sympa pour bâtir une marque ou une identité sur internet !
Les résolveurs DNS et les serveurs faisant autorité
Maintenant que l’on a vu qu’il faut une adresse IP pour que les machines puissent discuter, et qu’un serveur DNS sur le principe permet de faire le lien entre les noms et les adresses IP, il faut s’intéresser au fonctionnement de la résolution DNS.
Et pour comprendre ça, il faut d’abord que je vous explique les différents niveaux…
Les niveaux
Les noms de domaines sont écrits d’une certaine façon avec plusieurs niveaux. Quelques exemples de nom de domaine :
- www.wikipedia.fr
- translate.google.fr
- nanuq.me
- Tout d’abord le niveau « root » (la racine). On ne la voit pas car elle est représentée par un point et il est souvent invisible pour les usagers. Mais si on tape une commande sur un terminal on peut vite le voir.
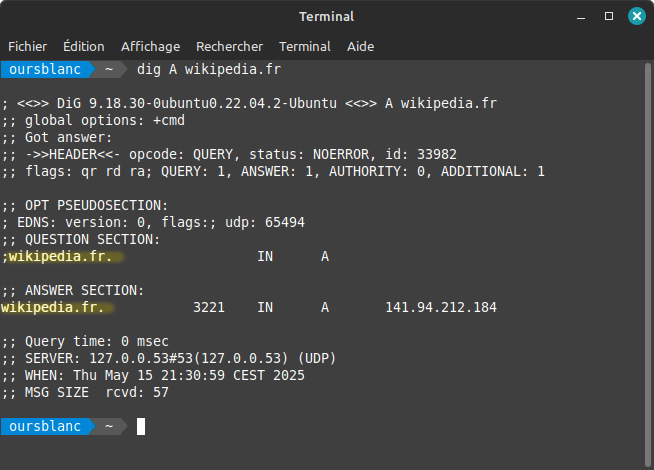
- Vient ensuite ce qu’on appelle le TLD (Top Level Domain) comme .fr, .com, .me, ou .ninja (oui il existe vraiment). On parle aussi d’extension mais techniquement, c’est un nom de domaine c’est d’ailleurs dans le nom : Top Level Domain
- Puis les domaines de deuxième niveau. Si on reprend les exemples précédents : google, wikipedia, nanuq
- Puis les domaines de troisième niveau. Avec les exemples précédents : www ou translate. On parle aussi de sous-domaine mais c’est techniquement un domaine de troisième niveau.
- Puis les domaines de quatrième… cinquième… etc etc…
En pratique, on utilise généralement 2 ou 3 niveaux (comme www.google.fr), mais techniquement, rien n’empêche d’avoir beaucoup plus, tant que le nom complet ne dépasse pas 253 caractères ! Un petit exemple avec une adresse fictive :
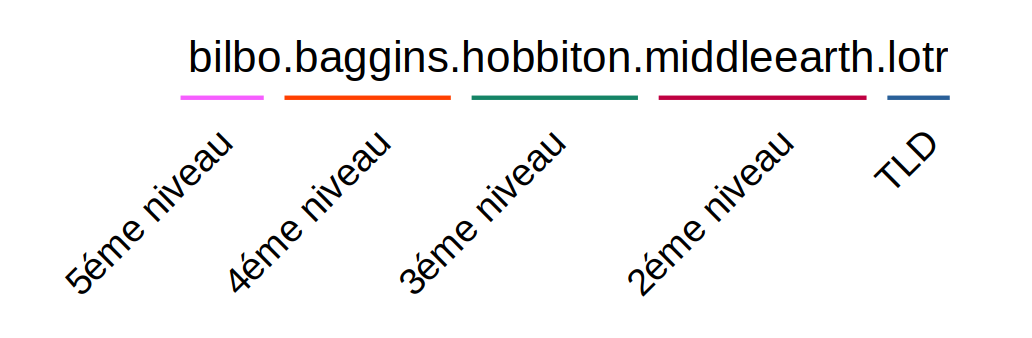
Les résolveurs DNS
Maintenant que l’on connaît la structure des noms de domaine, voyons comment c’est traduit en adresse IP.
Reprenons notre exemple de bilbo.baggins.hobbiton.middleearth.lotr
Au départ, la demande est faite à une machine qu’on appelle le résolveur DNS qui est généralement situé chez votre FAI, mais elle peut être aussi sur un réseau local d’entreprise, ou d’université par exemple.
Cette machine ne connaît pas l’adresse de bilbo.baggins.hobbiton.middleearth.lotr . Pour ainsi dire, elle ne sait rien. Elle est bête. Et tout ce qu’elle connaît c’est l’adresse des serveurs root. Et elle va donc demander successivement à plusieurs « personnes » :
- D’abord au serveur root (racine)
- Vous demandez alors : « Ô Vénéré Serveur Racine, connais-tu
bilbo.baggins.hobbiton.middleearth.lotr? » - Et le serveur racine vous répond « Ha non mon enfant, moi je connais seulement tous les domaines du premier niveau : les TLD. D’ailleurs voici l’adresse du serveur qui gère
.lotr… Lui il saura te renseigner ! »
- Vous demandez alors : « Ô Vénéré Serveur Racine, connais-tu
- Puis au serveur
.lotr- Vous demandez : « Ô Grand Serveur de Premier Niveau (TLD), connais-tu
bilbo.baggins.hobbiton.middleearth.lotr? » - Le serveur vous répond : « Ha non mon enfant, moi je connais seulement tous les domaines du deuxième niveau ! D’ailleurs, voici l’adresse du serveur qui gère
.middleearth.lotr… Lui il saura te renseigner ! »
- Vous demandez : « Ô Grand Serveur de Premier Niveau (TLD), connais-tu
- Puis au serveur
.middleearth.lotr- Vous demandez : « Ô Estimé Serveur de Deuxième Niveau, connais-tu
bilbo.baggins.hobbiton.middleearth.lotr? » - Le serveur vous répond : « Ha non mon enfant, moi je connais seulement tous les domaines du troisième niveau ! D’ailleurs, voici l’adresse du serveur qui gère
.hobbiton.middleearth.lotr… Lui il saura te renseigner ! »
- Vous demandez : « Ô Estimé Serveur de Deuxième Niveau, connais-tu
- Puis au serveur
.hobbiton.middleearth.lotr- Vous demandez : « Ô Respecté Serveur de Troisième Niveau, connais-tu
bilbo.baggins.hobbiton.middleearth.lotr? » - Le serveur vous répond : « Ha non mon enfant, moi je connais seulement tous les domaines du quatrième niveau ! D’ailleurs, voici l’adresse du serveur qui gère
.baggins.hobbiton.middleearth.lotr… Lui il saura te renseigner ! »
- Vous demandez : « Ô Respecté Serveur de Troisième Niveau, connais-tu
- Puis au serveur
.baggins.hobbiton.middleearth.lotr- Vous demandez en soupirant parce que ça commence à être long « Hé, toi là, tu connais
bilbo.baggins.hobbiton.middleearth.lotr? » - Le serveur vous répond : « Mais oui mon enfant ! Et voici son adresse IPv6 : 2001:0db8\:abcd:1234:5678:9abc\:def0:0001 »
- Vous demandez en soupirant parce que ça commence à être long « Hé, toi là, tu connais
Note : L’adresse et le nom sont fictifs
L’ensemble des serveurs auquel on a demandé notre chemin s’appelle des serveurs faisant autorité (à ne pas confondre avec le serveur résolveur) parce que ces serveurs ont une base de données (comme expliqué plus tôt) qui connaissent la liste de tous les domaines du niveau inférieur qui sont enregistrés chez eux.
Et ainsi, de proche en proche on sait retrouver l’adresse IP du site.
Et vous vous dites sûrement « Mais ça doit être super long ! » Et oui, ça l’est. Mais il faut savoir que le serveur résolveur met en cache les requêtes qu’il a déjà effectuées. Ça veut dire qu’il garde de côté certaines informations pendant un certain temps, pour ne pas aller redemander à chaque fois .
Dans notre exemple si dessus, si maintenant on veut accéder à map.hobbiton.middleearth.lotr et bien notre résolveur sait déjà qu’il faut demander à hobbiton.middleearth.lotr et il a déjà enregistré l’adresse du serveur faisant autorité sur ce domaine, et va donc lui demander directement sans repasser par racine, TLD, deuxième niveau, troisième niveau…
Youpi !
HTTP
Maintenant qu’on a récupéré l’adresse via le DNS, et qu’on sait envoyer des paquets vers cette adresse via TCP/IP, comment on envoie la demande ?
C’est au tour de HTTP (Hypertext Transfer Protocol) d’entrer en jeu.
Ce protocole permet de définir les règles pour échanger les documents web (pages, images, texte, etc…). Comme on l’a vu précédemment TCP/IP s’occupe du transport du paquet, par analogie, HTTP ça serait ce qu’on met dedans par exemple « Donne-moi la page d’accueil » ou « Envoie-moi telle image »
Le problème, c’est que avec HTTP, les demandes sont envoyées en clair, c’est-à-dire que n’importe qui de mal intentionné sur le réseau pourrait voir votre demande et la réponse. Un peu à la manière d’une carte postale : tout le monde peut voir ce qui est écrit dessus. C’est pourquoi on utilise HTTPS !
HTTPS & SSL/TLS
HTTPS pour Hypertext Transfer Protocol Secure permet de chiffrer les échanges entre le client et le serveur avec le chiffrement SSL/TLS.
SSL/TLS
SSL/TLS est un protocole qui permet de chiffrer les échanges. SSL (Secure Sockets Layer) est l’ancien nom du protocole qui n’est normalement plus utilisé. Et TLS (Transport Layer Security) est sa version moderne et sécurisée qui permet de protéger les données, d’assurer qu’elles ne soient pas modifiées, et de vérifier qu’on parle au bon serveur via un certificat.
Les certificats
Afin de s’assurer qu’on parle au bon serveur, et que notre requête n’est pas redirigée par des petits malins sur un autre serveur, on utilise un principe de certificat. Concrètement, lorsqu’on tente de se connecter à un serveur, ce dernier commence par envoyer un certificat. C’est en quelque sorte un document qui stipule : « Hey, je suis google.fr et voici ma clé publique ! D’ailleurs, ça été vérifié par une autorité de confiance ! »
Vous vous dites peut-être, mais n’importe qui peut dire que « Je suis google.fr faites-moi confiance ! » Et bien pas vraiment.
Parce que le navigateur va regarder la signature du certificat, et généralement on ne fait confiance qu’à des organismes reconnus comme Let’s Encrypt par exemple.
Si un vilain pirate voulait falsifier ce certificat, il faudrait que Let’s Encrypt lui donne sa signature. Or Let’s Encrypt va demander une preuve pour être sûr et certain qu’il fournit sa signature au propriétaire du serveur et pas à un vilain pirate. Et une des méthodes utilisées c’est de demander un enregistrement DNS spécifique. C’est-à-dire que le propriétaire du site doit ajouter une ligne dans l’annuaire du domaine « Le site web est à l’adresse 123.123.123.123 type A, et voici une preuve pour lets encrypt : Blablabla… »
Si on peut faire ça, c’est qu’on a les mots de passe pour aller faire ça et donc qu’on est propriétaire du serveur.
Le firewall
On a bien avancé dans notre voyage ! On a commencé par trouver l’adresse IP de notre serveur via les DNS, puis on a chiffré notre demande via HTTPS, et TCP s’est occupé de mettre tout ça dans des petits paquets et de les envoyer sur le réseau, et IP de trouver un chemin pour les distribuer !
Mais avant de pouvoir rentrer dans le serveur, les paquets passent souvent par un firewall (ou pare-feu en français).
Ce pare-feu agit comme un filtre à l’entrée du serveur. Il vérifie qui a le droit d’entrer (on peut filtrer par adresse, par port, par protocole par exemple) et permet ainsi de bloquer certaines attaques, ou du spam.
C’est une véritable barrière de sécurité qui permet de bloquer certaines connexions avant même qu’elles atteignent le serveur.
Typiquement le protocole HTTPS utilise le port 443, on peut donc paramétrer le serveur pour dire « Je ne veux accepter que des communications chiffrées et sécurisées, donc je n’accepte que les connexions entrantes sur le port 443. »
Ce qui revient à dire que si on utilise HTTP (sans le S) sur le port 80, le pare-feu bloquera l’entrée et on restera dehors, porte close !
On se sert la main ?
Une fois le pare-feu passé, le client ne parle pas encore directement en HTTPS totalement chiffré. La première chose qu’il fait, c’est demander le certificat du serveur. Alors le serveur lui présente gentiment (prouvant son identité comme expliqué plus haut) ; et le client vérifie que tout est correct (signature par une autorité de confiance, domaine, etc.). Si tout est bon, le chiffrement est activé.
La vraie requête HTTPS commence alors : tout est désormais chiffré et donc illisible pour les curieux.
C’est ce qu’on appelle le TLS Handshake dans le jargon
Une petite analogie :
C’est comme envoyer une carte postale disant :
« Salut copain, on se parle avec notre super code secret pour les prochains échanges ? »
Et dès que votre ami répond oui, vous commencez à chiffrer tous les échanges suivants.
Le load balancer
Ça y est ! On a passé la « sécurité » on est dans le serveur ! On arrive alors à une espèce d’aiguillage. Car imaginons que le site est tellement populaire qu’un seul serveur ne suffit pas à traiter toutes les demandes; il faudrait répartir le flux de visiteurs vers plusieurs serveurs. Un peu comme au supermarché, y’a plusieurs caisses enregistreuses pour gérer le flux des visiteurs, et on dispatch les visiteurs vers les caisses libres.
Le load balancer va donc recevoir toutes les connexions entrantes pour les répartir entre plusieurs serveurs derrière lui. Et pour ça il peut utiliser différents algorithmes :
- Round Robin En Round Robin, le load balancer va envoyer les clients sur les serveurs tour à tour, de manière cyclique sans vérifier leur charge, leur temps de réponse, ou d’autres paramètres. C’est utilisé parce que c’est très simple à mettre en place mais c’est pas le plus optimal
- IP Hash Le load balancer va envoyer les requêtes d’une même IP toujours sur le même serveur. Ça permet une continuité et une stabilité pour le client
- Least Connection Le load balancer va envoyer les requêtes sur le serveur qui gère le moins de client à la fois. Une analogie par rapport au super marché : « La caisse avec le moins de client »
- Least response time Le load balancer va envoyer les requêtes sur le serveur qui répond le plus rapidement. C’est très utilisé quand il y a des serveurs un peu partout dans le monde, et qu’on veut se connecter au serveur le plus proche géographiquement de chez soi.
- Least bandwidth Le load balancer va envoyer les requêtes sur le serveur qui utilise le moins de bande passante.
Il existe d’autres façons de faire, mais ce sont les algorithmes les plus courants.
Le load balancer agit donc comme un répartiteur intelligent, pour que personne ne fasse la queue trop longtemps et que le site reste rapide et disponible, même en cas de forte affluence.
Le web server
On arrive enfin au web server après toutes ces péripéties !
C’est le logiciel qui écoute sur un port HTTP ou HTTPS (80 ou 443 par défaut donc) et qui s’occupe de recevoir les requêtes HTTP, de servir des pages, ou dans des cas plus élaborés de transférer la requête à une application. (On parle alors de reverse proxy : le web server devient un intermédiaire entre le client et l’application).
Voici les web server les plus utilisés :
- Nginx
- Apache
- Caddy
Application server
Partons du principe que le web server ne nous a pas servi une page mais a fait office de reverse proxy pour nous envoyer vers un serveur applicatif (ou application server)
C’est le serveur qui contient l’application comme son nom l’indique, et la logique métier, il va effectuer les calculs, traiter les données. Par exemple quand on remplit un formulaire, le web server va transmettre la demande et l’application va lire les données, interagir avec la base de données, préparer une réponse, et renvoyer le tout au serveur web.
Typiquement, c’est ce qui se passe avec une API à la différence que l’API ne renvoie pas des pages web, mais des données (souvent au format JSON)
La base de donnée
On arrive presque à la fin du voyage, terminons par la base de données. Le serveur applicatif ne travaille pas tout seul. Il doit souvent stocker et gérer des informations (imaginez que vous créez un compte sur un site, il faut bien stocker votre pseudo quelque part) ; et c’est la base de données qui gère ça.
C’est une espèce de grosse bibliothèque, ou de gros tableau Excel qui enregistre des informations (Votre nom, votre adresse, vos commandes sur un site marchand etc…). Cette base de données s’occupe d’aller chercher ses informations de les servir quand on les demande, et de les mettre à jour le cas échéant.
Quelques exemples de base de données :
- MySQL : la plus courante
- MariaDB : fork communautaire de MySQL
- PostgreSQL : pour des projets plus complexes
- MongoDB : stockage des documents à la manière de fiche au format JSON
- SQLite : pour des petites bases de données locales
Voila, c’est fini !
Pfiou ! Notre balade à cheval touche à sa fin !
On a tapé « https://www.google.fr », le serveur DNS nous a trouvé l’adresse, faire notre demande avec HTTPS et avec TCP/IP on a pu trouver un chemin et envoyer les paquets contenant notre demande !
Le firewall nous a laissé passer sur le port 443, puis le load balancer nous a redirigé vers un serveur disponible, qui a traité notre demande dans une application, utilisé des données venant d’une base de données, et nous a servi la page demandée !
J’espère que cet article vous aura plu, que vous aurez appris deux ou trois trucs.
Et pour conclure tout ça voici un beau schéma pour récapituler tout ce que j’ai expliqué !
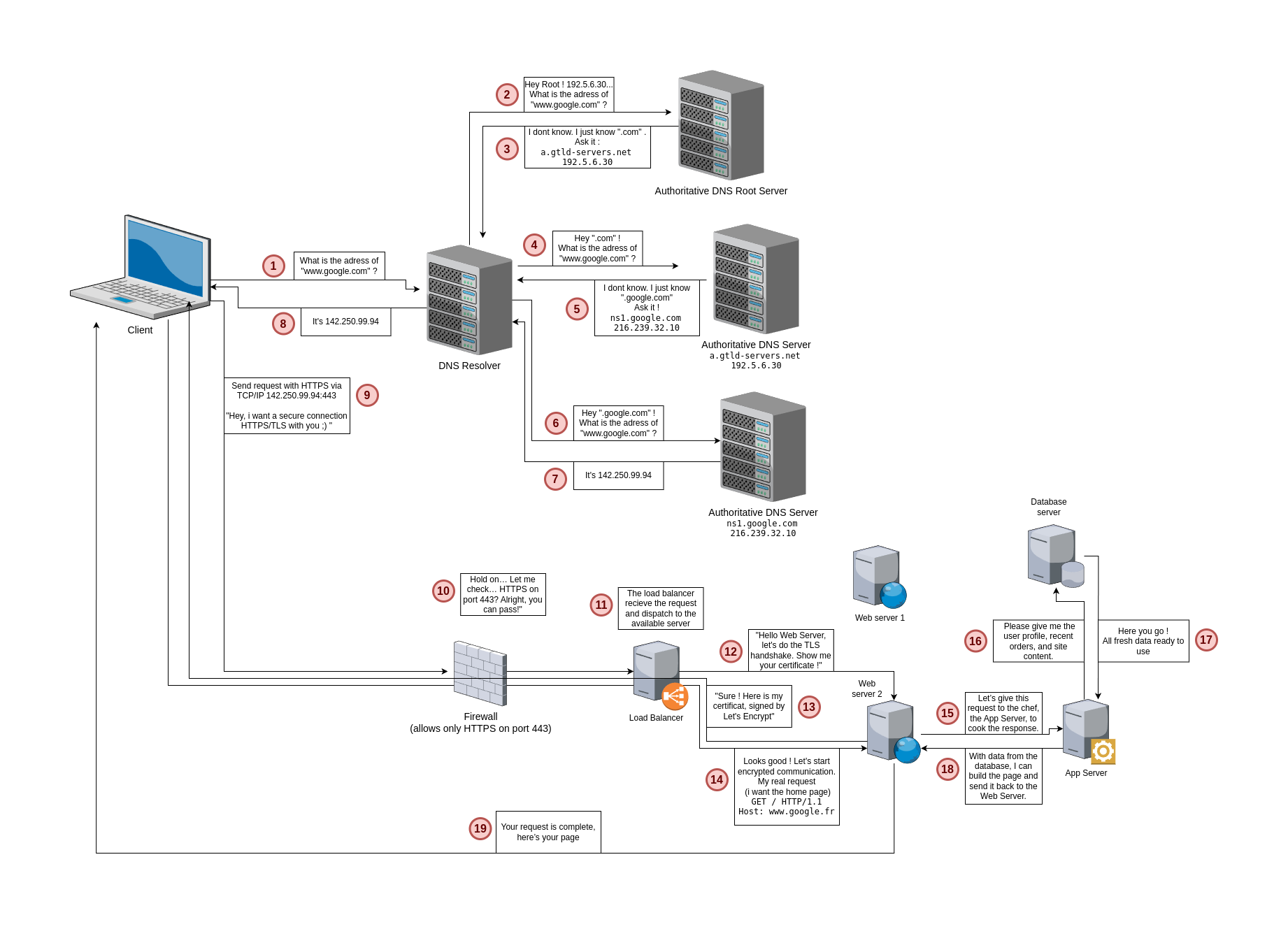
Et d’ici là : n’oubliez jamais d’apprendre !





Comments by OursBlanc