
🗓️ Note : Cet article est une archive importée de mon ancien blog. Certaines informations peuvent ne plus être à jour.
Ou comment faire du traitement par lot afin de récupérer toutes les cartes de Magic en Français ; tout en apprenant, et en s’amusant sur un cas pratique. Le tout, détaillé afin d’expliquer la démarche et de vous permettre de hacker ce mode opératoire afin de l’appliquer à d’autres objectifs.
Si vous voulez la réponse courte, allez directement à la conclusion 🙂
Introduction
Dans mon dernier article, je vous parlais de Cockatrice. Ce logiciel permettant de jouer (entre autre) à Magic en ligne et d’accéder à toutes les références de cartes possibles. Avant de conclure, je vous expliquais qu’on pouvait mettre les cartes en français… Enfin, une partie seulement. Voyons ensemble comment on peut faire pour obtenir toutes les cartes en français. Néanmoins avant d’aller plus loin, je tiens à préciser plusieurs points :
- Je ne suis pas développeur. Je fais un peu de code des fois pour rigoler sur mon temps libre ; mais disons que je code avec les pieds. J’ai pas mal bidouillé avec le langage VBA sur Excel. Autant dire : c’est pas glorieux.
- Par la suite, on va utiliser Python. En gros tout ce que j’ai fait avec Python c’est un « Hello World » il y a 5 ans…
- J’imagine qu’il y a plein d’autres moyens d’arriver au résultat final. C’est une façon de faire, c’est certainement pas la meilleure.
- Je suis peut être en train de réinventer la roue. Il est fort probable qu’il existe déjà une solution quelquepart sur les internets pour récupérer toutes les cartes en français. En réalité, le résultat final m’importe peu. Ce que je souhaite c’est d’une part la satisfaction de l’avoir fait moi même ; et d’autre part, d’expliquer comment j’y suis parvenu.
- J’ai voulu également retranscrire les méandres du processus. Les petits fails, les fois où je m’engage dans une mauvaise route. Je trouve ça particulièrement pertinent de voir les erreurs et s’améliorer.
- J’espère que cet article vous apprendra des choses, et vous donnera des idées pour d’autres projets. N’hésitez pas à détourner son utilité première pour arriver à d’autres fins.

La démarche
Rappel
Dans l‘épisode précédent, (je vous invite à aller le lire d’ailleurs) on avait vu qu’on pouvait modifier la base de donnée de Cockatrice, en lui demandant d’aller chercher les cartes dans la langue du client.

Je vous avais alors dit qu’il fallait retirer les liens par défaut et le remplacer avec ce lien ci :
https://api.scryfall.com/cards/!setcode_lower!/!set:num!/!sflang!?format=image&face=!prop:side!
Comment j’avais fait ?
Seulement voilà, vous vous doutez bien que j’ai pas sorti ça de mon chapeau magique. Pour découvrir ce lien, j’ai farfouillé un peu. Sur le screenshot ci dessus, à gauche du repère [1] il y a un lien : « Comment ajouter une URL personnalisée » (Oui il est bleu foncé sur anthracite, c’est pas très lisible je vous l’accorde).
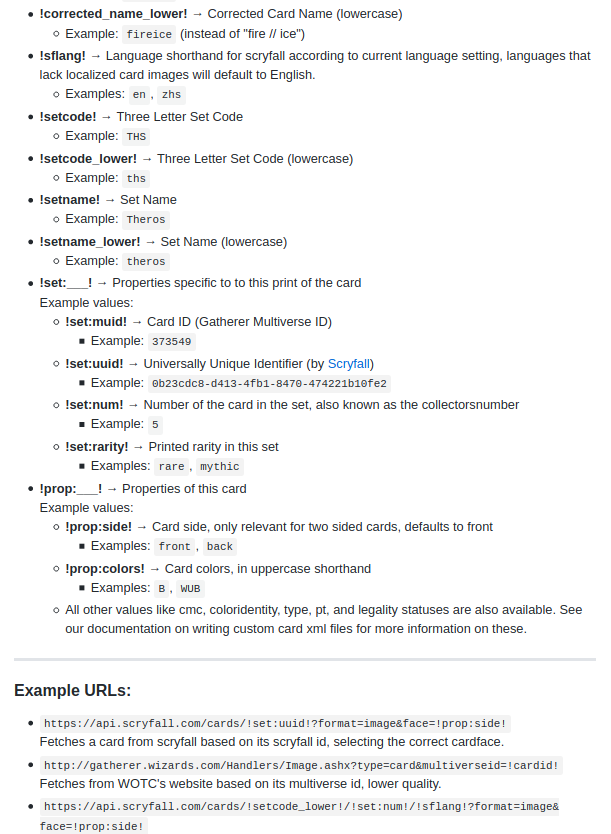
On arrive sur le github de Cockatrice (en anglais). On y apprend que l’on peut modifier les liens avec quelques paramétres. Celui qui nous intéresse le plus est le suivant :
!sflang! → Language shorthand for scryfall according to current language setting, languages that lack localized card images will default to English.
Examples:
en,zhs
Traduction : Abréviation de scryfall selon le réglage de la langue actuelle, les langues qui n’ont pas d’images de carte localisées seront par défaut l’anglais.
Bon, je comprends pas tout, mais ca parle de langues, de cartes par défaut en anglais… Ca sent bon tout ça ! Si on continue de scroller sur cette page on arrive à quelques exemples d’URL, et un à particulièrement retenu mon attention !
https://api.scryfall.com/cards/!setcode_lower!/!set:num!/!sflang!?format=image&face=!prop:side!
Searches for the setcode and setnumber together with the language, fetches an image in the currently used client language.The
!sflang!property can also be manually exchanged for a supported language code, e.g.enorja, to separate it from the current language setting.
Traduction : Recherche le setcode et le setnumber ainsi que la langue, recherche une image dans la langue du client actuellement utilisée. La propriété !sflang ! peut également être échangée manuellement contre un code de langue pris en charge, par exemple en ou ja, pour le séparer du paramètre de langue actuel.
Vous reconnaissez le lien qu’ils donnent en exemple ? C’est lui qu’il faut rentrer dans le logiciel ! C’est comme ça que je l’ai trouvé. Nous, notre logiciel est en français, on va garder le paramétrage par défaut et on va pas s’embêter à manuellement changer la langue.
Pourquoi tout n’est pas traduit ?
Bon, ensuite je me suis demandé « Mais pourquoi on a pas toutes les cartes en français ? » . Rappelez vous de ce qu’on vient de voir ci dessus, j’ai cliqué sur le lien qu’ils donnaient dans les exemples : « supported language code« .
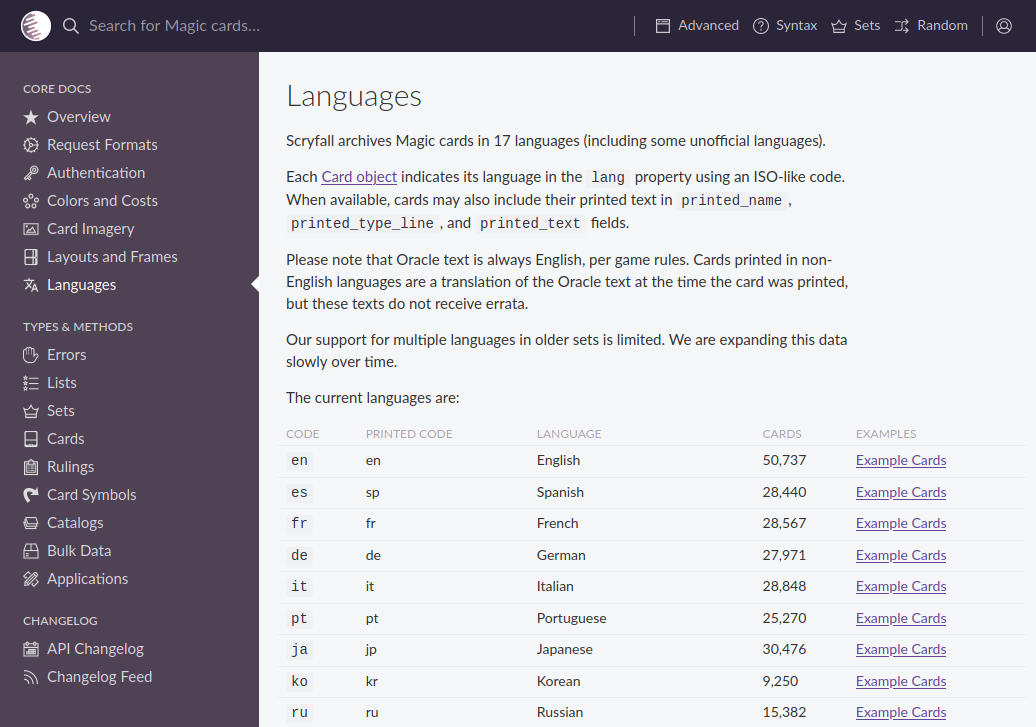
On arrive sur le site de Scryfall. Et on apprend tout un tas de chose ! Petite traduction :
Archives de Scryfall cartes Magic en 17 langues (y compris certaines langues non officielles).
Chaque objet Card indique sa langue dans la propriété lang en utilisant un code de type ISO. Lorsqu’elles sont disponibles, les cartes peuvent également inclure leur texte imprimé dans les champs printed_name, printed_type_line, et printed_text.
Veuillez noter que le texte Oracle est toujours en anglais, selon les règles du jeu. Les cartes imprimées dans des langues autres que l’anglais sont une traduction du texte Oracle au moment où la carte a été imprimée, mais ces textes ne reçoivent pas d’errata.
Notre support pour les langues multiples dans les jeux plus anciens est limité. Nous développons lentement ces données au fil du temps.
J’en déduis plusieurs choses :
- C’est une base de donnée comprenant tout un tas de cartes Magic en différentes langues (avec même quelques traductions non officielles)
- Dans le tableau récapitulatif, on voit qu’il y a 50.737 cartes en anglais, et « seulement » 28.567 cartes en français. Environ 50% à la grosse louche. En effet, certaines cartes n’ont jamais été traduite. (Les cartes des extensions humouristiques par exemples). Mais le soucis ne vient pas de là car ce sont des cartes qui ne sont que trés rarement jouées . Le probléme c’est que le site Scryfall ne contient pas toutes les illustrations en Français . Voici un exemple . On remarque que certaines des ces anciennes cartes ont l’illustration avec le texte en francais, et pas d’autres.
Voilà donc pourquoi tout n’est pas traduit en français. Est ce qu’on pourrait pas s’arranger pour compléter la collection ?
Comment fonctionne Cockatrice ?
Avant d’aller plus loin, je me suis intéressé au fonctionnement du logiciel Cockatrice. Dans les paramètres de Cockatrice, j’ai remarqué une option intéressante : Répertoire des images . Allons y jeter un oeil.
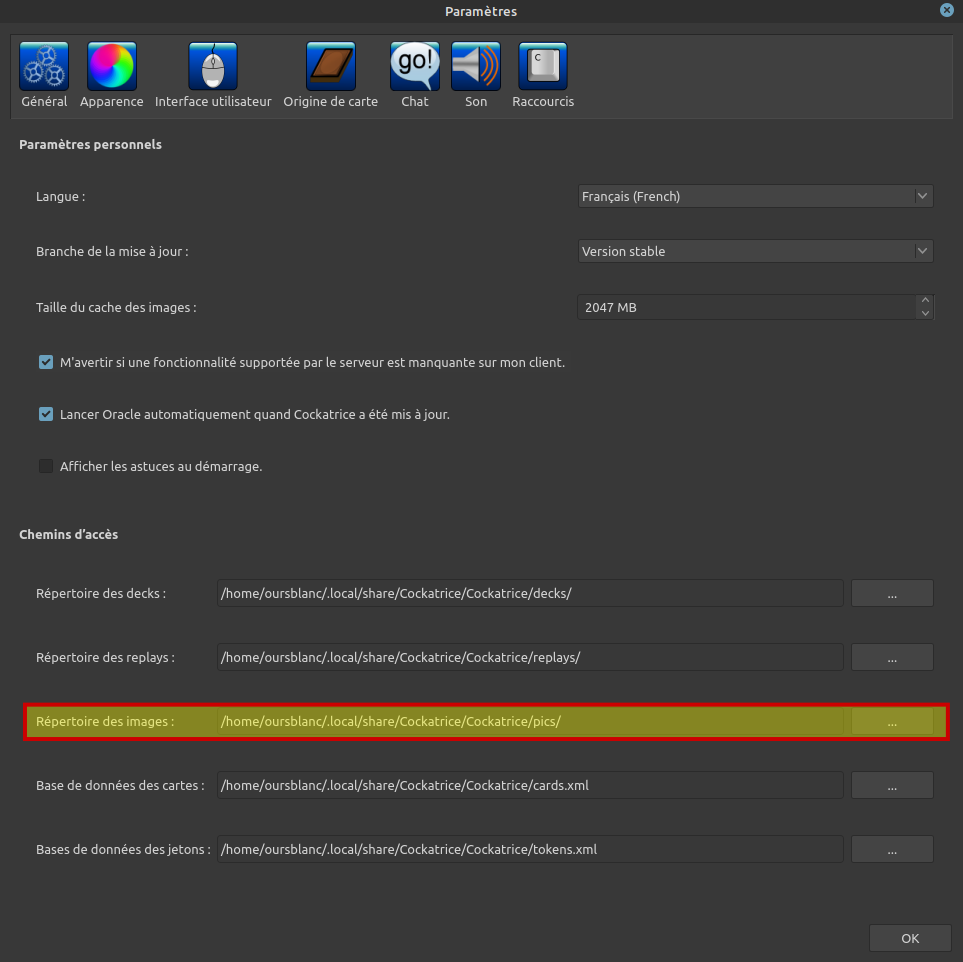
On découvre alors un dossier, comprenant deux sous dossiers :
- CUSTOM
- downloadedpics
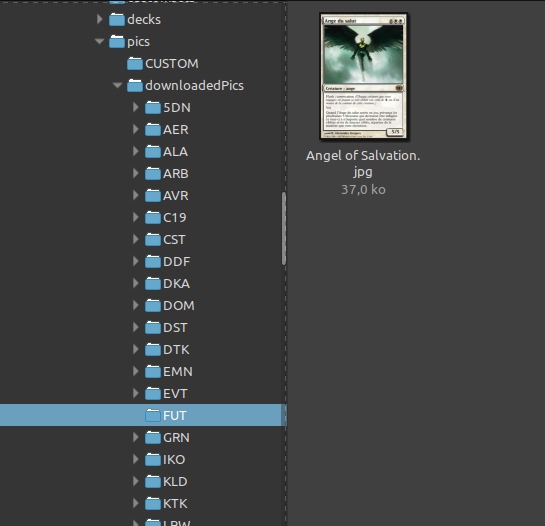
Le dossier CUSTOM etant vide, je m’intéresse au dossier « downloadedpics » littéralement : « images téléchargées » . Et voilà ce qu’on découvre !
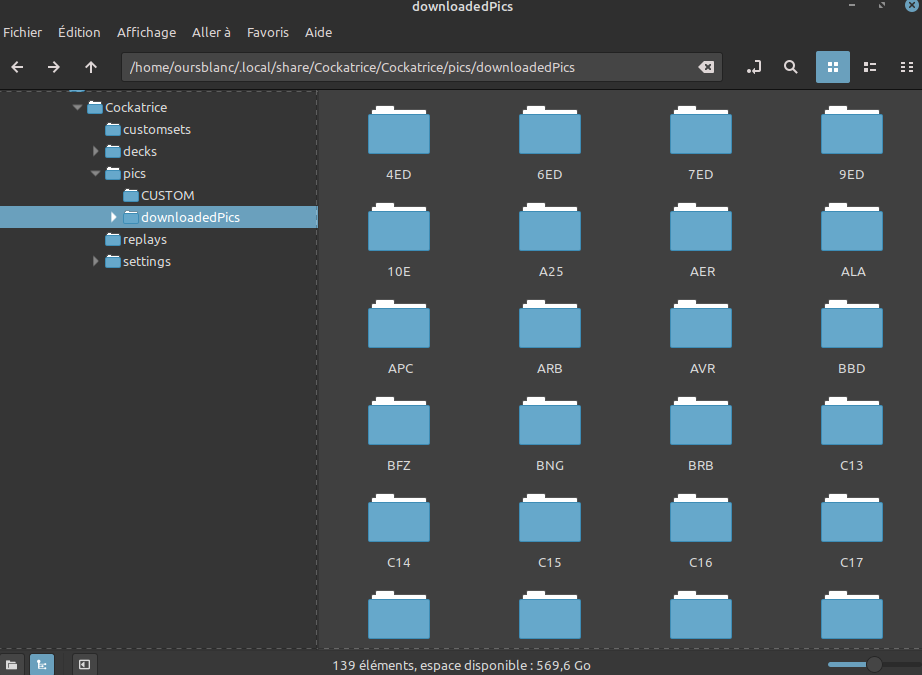
Tout un tas de dossier avec d’étranges noms de 3 caractéres… Et si l’on en ouvre un au hasard :
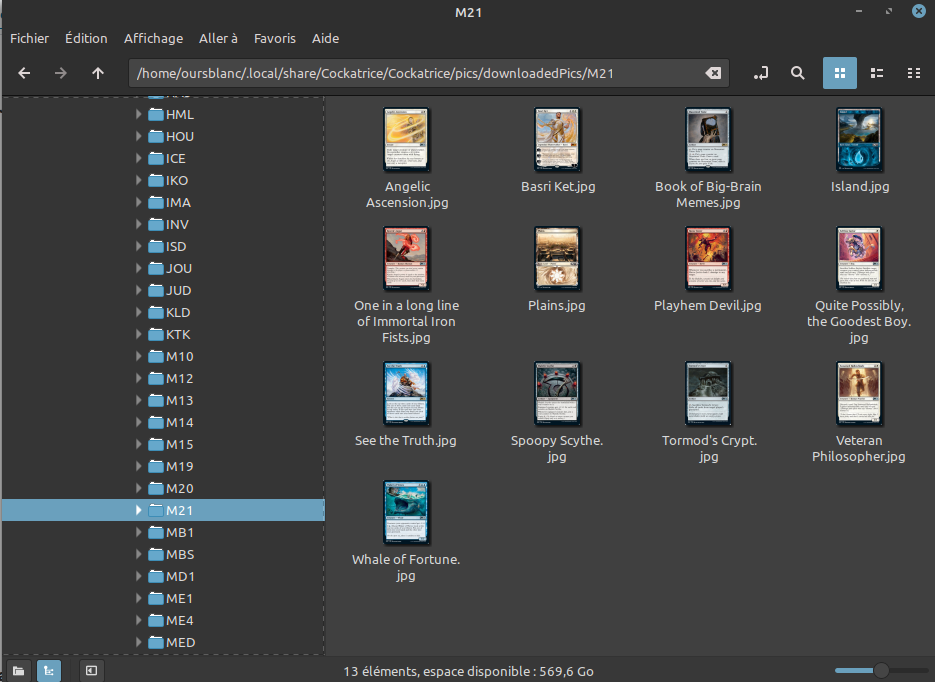
Des cartes magic en .jpg ! Certaines sont en français; et si il n’existe pas de versions française, vous allez avoir un joli bandeau sur la carte comme on l’avait vu dans le précédent article :

J’en déduis que le logiciel affiche l’illustration qui est contenue dans un de ces dossiers. Il reconnait l’image avec son nom (en anglais).
Mais c’est quoi tout ces dossiers ?
Évidemment on pourrait se dire que tout serait plus simple si toutes les cartes étaient dans le même dossier. Ici, on remarque qu’il y a tout un tas de dossier avec des noms étranges de trois caractères. Ça ne vous évoque peut être rien, mais si vous jouez à Magic depuis un moment comme moi, alors ca doit vous parler.
Chaque année, la société Wizard Of The Coast (filiale de Hasbro derrière Magic) édite de nouvelles cartes. Parfois il s’agit de réédition, parfois de cartes totalement inédite. Afin de s’y retrouver, on retrouve dans le coin droit de la ligne de type : le symbole d’extension. De plus, selon la couleur de ce symbole, vous pouvez connaitre la rareté de la carte.

Chaque édition est donc accompagnée d’un petit pictogramme pour la reconnaître. Vu que ce n’est pas évident de redessiner les petits pictogrammes sur un clavier d’ordinateur, on peut aussi désigner les extensions via un code de 3 caractères. Voici quelques exemples :
- M21 pour l’édition Magic Core 2021
- IKO pour l’édition Ikoria
- DTK pour l’édition Dragon Of Tarkir (Dragons de Tarkir)
- OTW pour l’édition Oath of the Gateway (Le serment des sentinelles)
- MRD pour l’édition Mirrodin
Maintenant que l’on sait ça, on sait que chaque image doit comporter les caractérisitques suivantes :
1 – être dans le bon dossier correspondant à son édition
2 – avoir le nom en anglais avec les majuscules, les espaces etc…
3 – être en .jpg
Les cartes : c’est comme les champignons. Faut connaître les bons coins !
L’idée, ca serait de télécharger les scans des cartes en français, et de les mettre dans les dossiers correspondant. Mais où est ce qu’on va trouver ça ? Il existe plusieurs sites spécialisés ; voici les plus connus en France (et j’imagine dans la francophonie…) :
- Magic-Ville
- Magic Corporation
- La Secte des Magiciens Fous (SMF pour les intimes)
- Lotus Noir
Il en existe évidemment d’autres mais je vais pas tout passer en revue… Sur ces sites, vous pouvez rechercher des cartes via les moteurs de recherches intégrés ; et généralement l’illustration adjointe sera le scan de la carte en français. La qualité n’est pas toujours parfaite mais c’est mieux que rien non ?
On prend quoi alors ?
Vous vous doutez bien qu’on va pas s’amuser à télécharger manuellement les cartes une à une. Mais on va faire du traitement par lot. Et comme je suis malin, je vais m’arranger pour avoir le moins de boulot à faire. Nous allons donc inspecter nos 4 candidats (les sites cités ci dessus) et voir comment ils fonctionnent.
Dans le navigateur internet Firefox, on peut faire clic droit sur un élément d’une page internet (texte, photo, bouton , lien etc…) et cliquer sur « Afficher l’élélement » pour voir le code HTML qui a derriére tout ça. (Si vous n’utilisez pas Firefox, faites une petite recherche sur les internets pour trouver comment faire avec votre navigateur préféré) . Pour la suite, quelques connaissances en HTML sont utile mais on peut faire sans.
Candidat : SMF
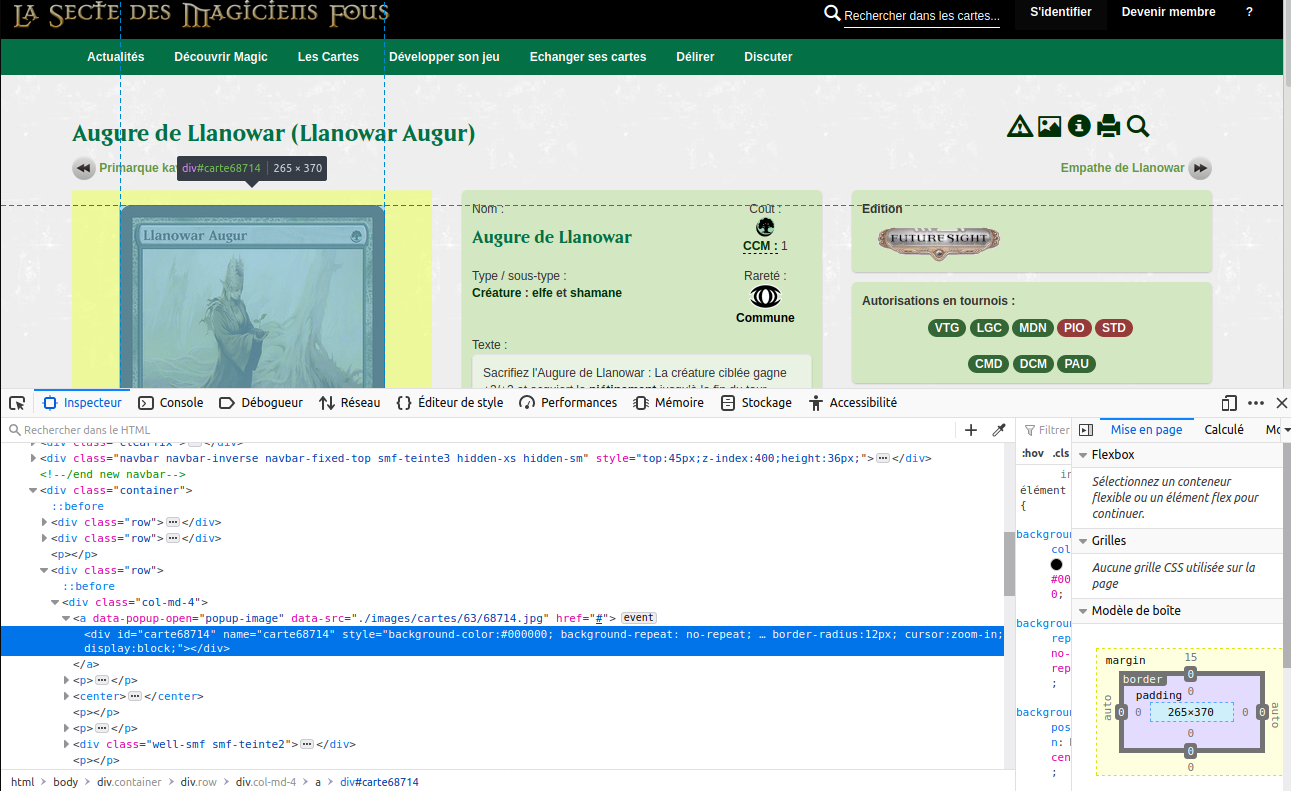
On voit que notre image est dans un <div>… C’est un peu bizarre je m’attendais à quelquechose du genre img src = « leliendel’image ». Bon, je suis pas trés bon en HTML, j’y comprends rien, candidat suivant !
Candidat : Magic Corpo
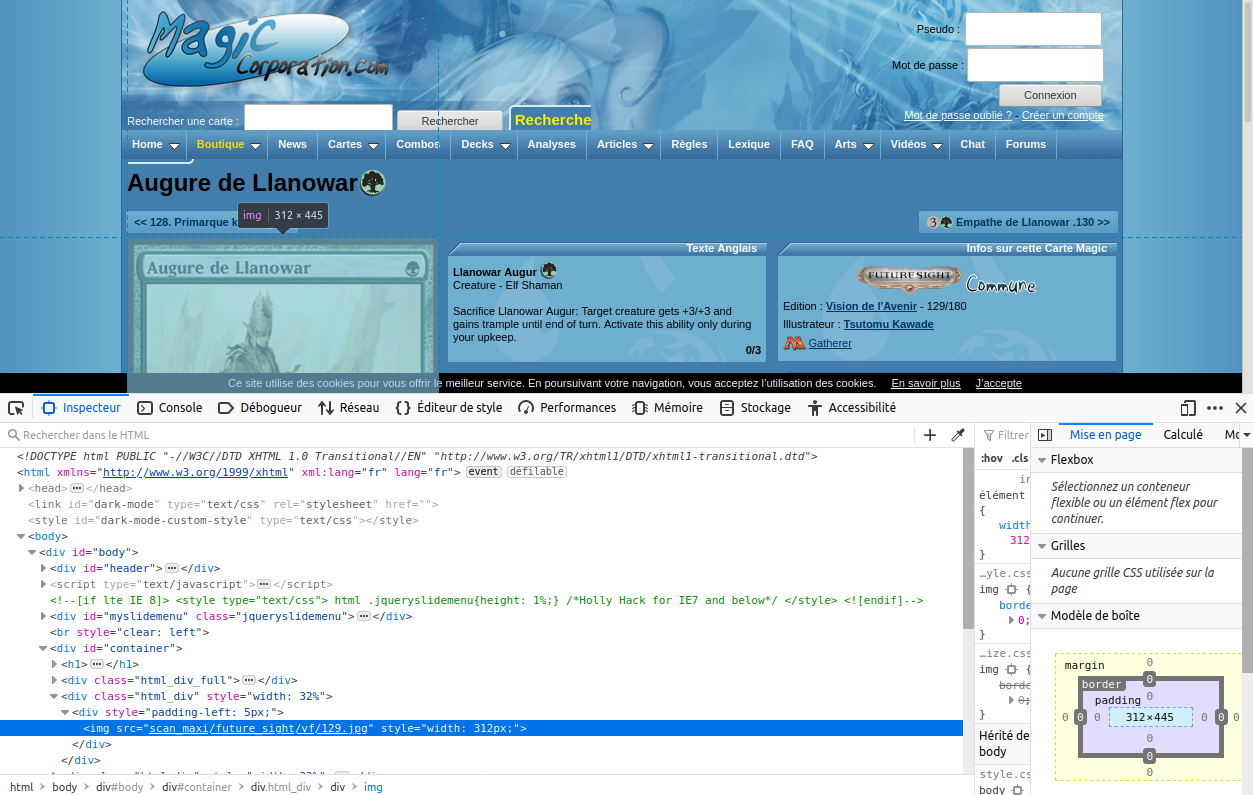
Là, on voit ce que j’attendais, une belle balise <img src = « blablabla »> Il y a l’extension de la carte; c’est une bonne chose ! Et un numéro qui définit la carte… Bon ok. Voyons voir les autres
Candidat : Lotus Noir
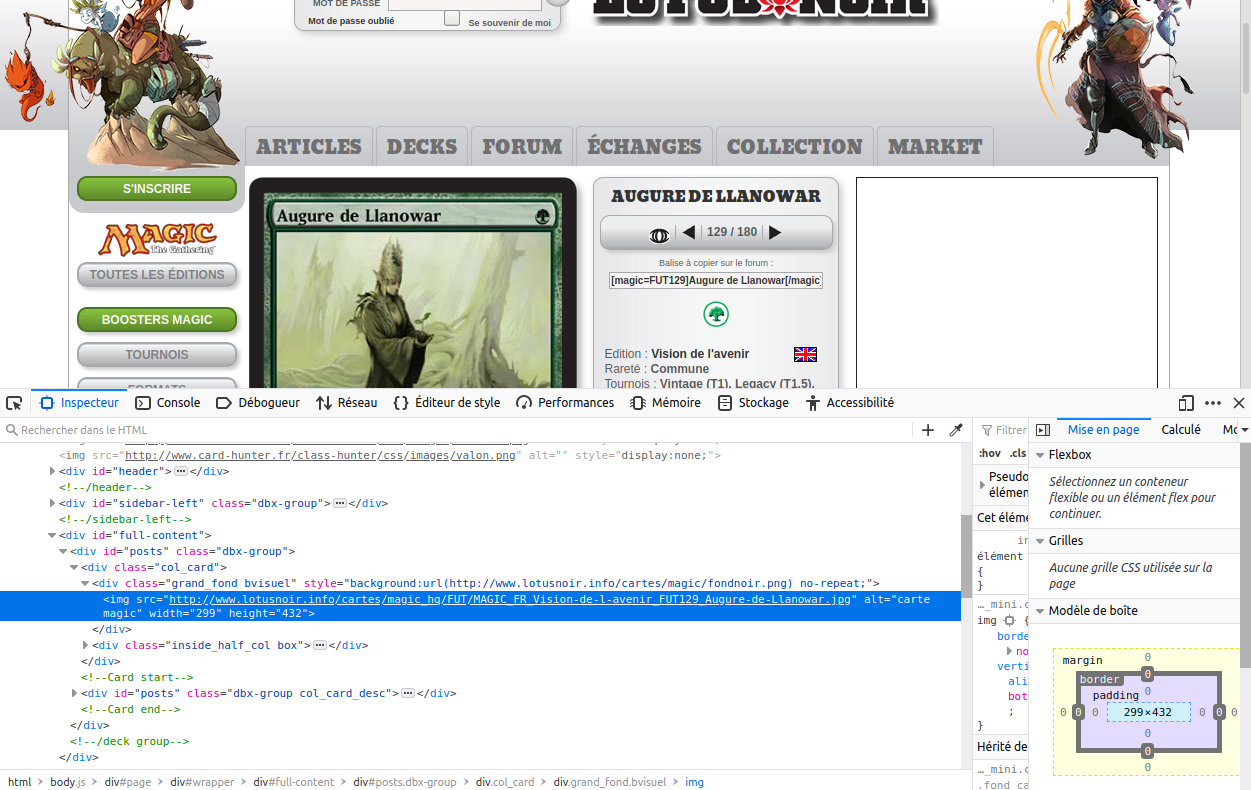
Là, on voit que le lien est encore plus compliqué, le nom de la carte est écrite en français, avec un nom à rallonge (et pas de numéro pour identifier la carte). Mais on remarque que l’extension est indiqué avec le fameux code de 3 caractéres ! En effet FUT désigne l’extension Future Sight. Ca c’est pratique tout de même !
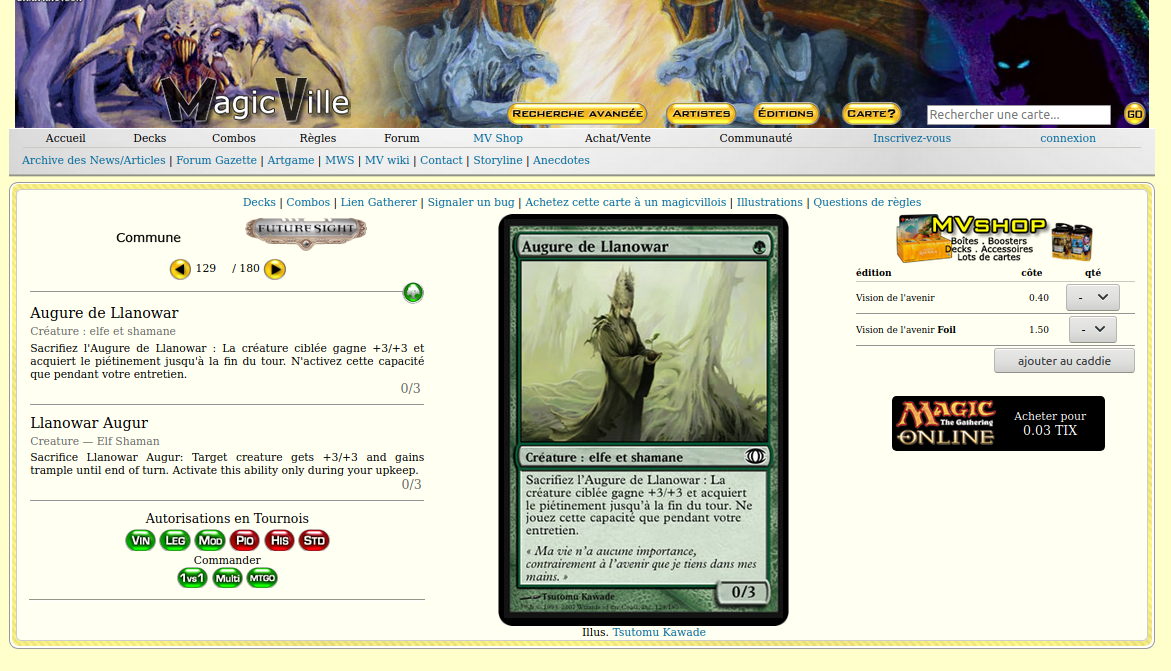
Candidat : MagicVille
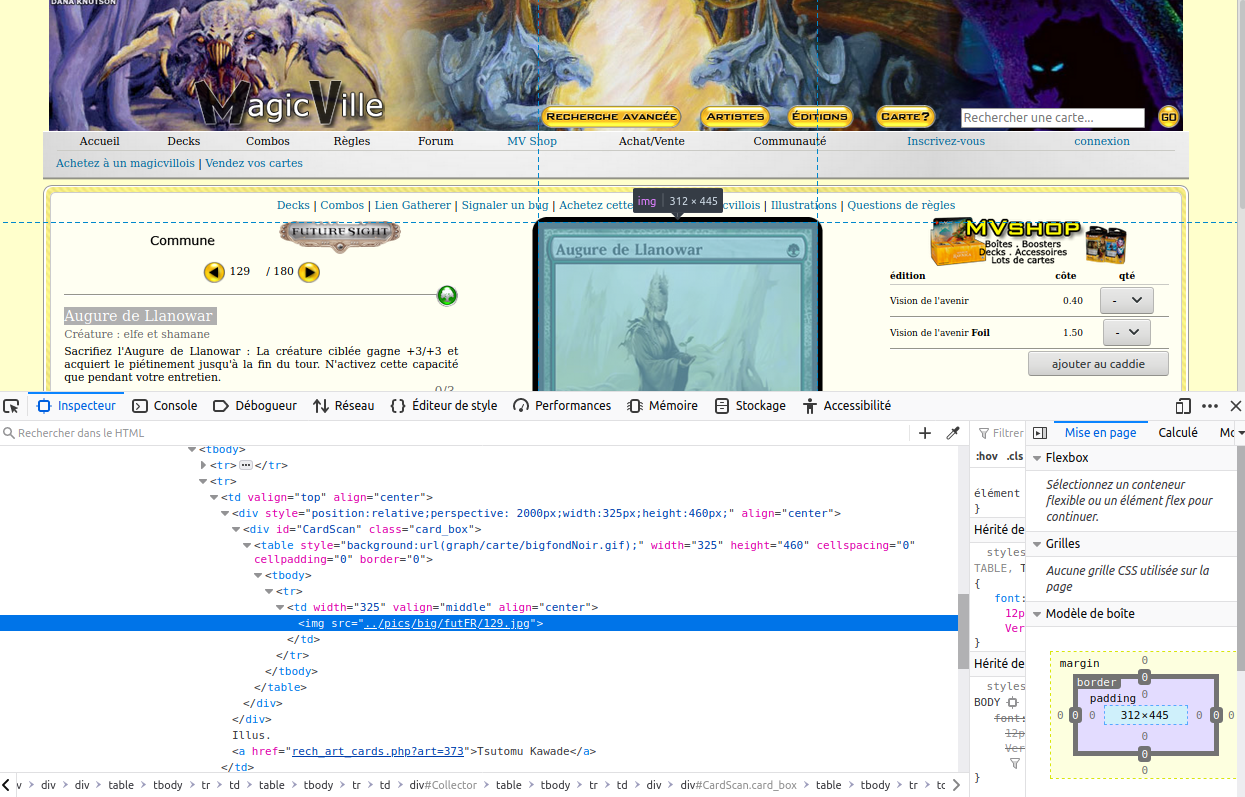
Voyons voir. Ha ! Là, c’est beaucoup plus court, et plus précis ! on a le trigramme de l’extension suivit de FR pour indiquer que la carte est en français ; et à la fin de tout ça un numéro qui identifie la carte.
MagicVille en finale !
Je sélectionne la solution MagicVIlle :
- Lien simple (extension + FR + numéro)
- Inconvénient c’est le FR qui se balade au milieu du lien justemment…
Faisons quelques tests, reprenons le lien de notre carte :
https://www.magic-ville.com/pics/big/futFR/129.jpgDans cette URL, on voit le site web, puis un répértoire « pics » qui doit contenir les images, puit le répertoire « big » qui doit contenir des images en grand formats, et enfin futFR et un numéro. J’en déduis que fut signifie l’extension Future Sight, et FR la langue. Si je remplace futFR par fut je devrais avoir la carte en anglais ? Testons !
https://www.magic-ville.com/pics/big/fut/129.jpgBingo ! Maintenant, on va essayer de trouver la première carte de l’édition fut (Future Sight), ça devrait normalement être
https://www.magic-ville.com/pics/big/fut/1.jpg Ha… Ça marche pas ! Essayons de comprendre pourquoi !
Dans le site MagicVille, je vais dans la page consacrée aux différentes éditions et je recherche l’édition Future Sight . On nous affiche la liste de toutes les cartes de cette édition, je sélectionne la première carte à savoir l’Ange du Salut. Examinons le lien de la carte… Il se termine par 001.jpg et non pas 1.jpg ! Du coup, le lien corrigé :
https://www.magic-ville.com/pics/big/fut/001.jpgYoupi ! Et si je le veux en français, je rajoute FR et ca donne ça :
https://www.magic-ville.com/pics/big/futFR/001.jpgEt maintenant, si je veux afficher une carte de l’extension Mirrodin ? Le trigramme de Mirrodin est MRD. Essayons ça :
https://www.magic-ville.com/pics/big/mrdFR/001.jpgHa, ben ca marche pas… Qu’est ce qu’il se passe ? Une nouvelle fois, je fais une recherche par éditions, et je me retrouve sur la liste de Mirrodin. Si l’on clique sur n’importe quelle carte, on verra que bien que la carte existe en français, le scan sur Magic-Ville est en anglais… Malédiction ! On aurait fait tout ça pour rien ?
Patience jeune padawan ! C’est déjà mieux que rien, voyons si l’on peut compléter notre collection avec un traitement par lot…
Le gros du boulot
Définissons des objectifs
Bon, maintenant réfléchissons à un programme. Définissons ce qu’il doit faire :
1 – Balayer toute une série de lien
2 – Télécharger l’image
3 – La nommer avec le non nom
4 – L’enregistrer au bon endroit
On pourrait améliorer ça en rajoutant des conditions : si la carte est déjà en français dans la base de donnée Scryfall, on s’embête pas à la télécharger. Même chose si la carte n’est pas dispo en français.
Simplifions le problème
Avant de m’embarquer dans un logiciel super complet avec plein d’option, je vais simplifier le problème en essayant une chose simple. Télécharger toutes les cartes d’une extension.
On l’a vu précédemment, sur Magic-Ville les liens vers les images ressemblent à ceci :
https://www.magic-ville.com/pics/big/futFR/129.jpgDu coup, il faudrait juste changer le numéro de l’image et faire toutes les combinaisons : 001,002,003 etc… pour tout télécharger. Évidemment, on va pas faire ça à la main.
Pour nos tests, on va juste essayer de télécharger quelques unes des premières cartes. Une fois encore, c’est pour simplifier le problème et déjà voir ce qu’on peut faire avec ça.
Quel langage on utilise ?
Il existe tout un tas de langage de programmation, j’ai choisis le Python. Pourquoi ? Parce qu’il est très utilisé, je trouverais plein d’aide en ligne; et qu’il est « relativement simple » à assimiler. On dit que c’est un langage de « haut niveau ».
Alors évidemment pour la suite, c’est mieux si on connaît un peu les langages de programmation, par exemple si on sait ce que c’est qu’un IF , un LOOP, ou un booléen… Vous trouverez tout un tas de tutoriel pour apprendre les rudiments du Python. Faut pas avoir peur, j’y connais rien moi non plus et j’ai commencé par là… Le but de cet article n’est pas de vous apprendre à utiliser le python, vous verrez donc ci dessous ma démarche pas à pas et non pas une explication détaillée de chaque commande. Pour info, j’utilise Python3 (choix arbitraire) et Spyder pour m’aider (un logiciel pour aider à coder en Python; j’ai choisis ça au pif…)
C’est parti !
Mon premier bout de programme va tenter de générer automatiquement les adresses pour télécharger les images. Mais vu que je suis vraiment une quiche, je vais encore simplifier le problème, je vais déjà essayer d’incrémenter des chiffres de 1 à 10…
Je me suis rappelé de mes bases de Python et je me suis aidé de ça. Voilà à quoi ca ressemble : (faites attention à l’indentation du code !)
Si vous voulez tester le code, utiliser ce site par exemple vous verrez ce résultat (à droite) :
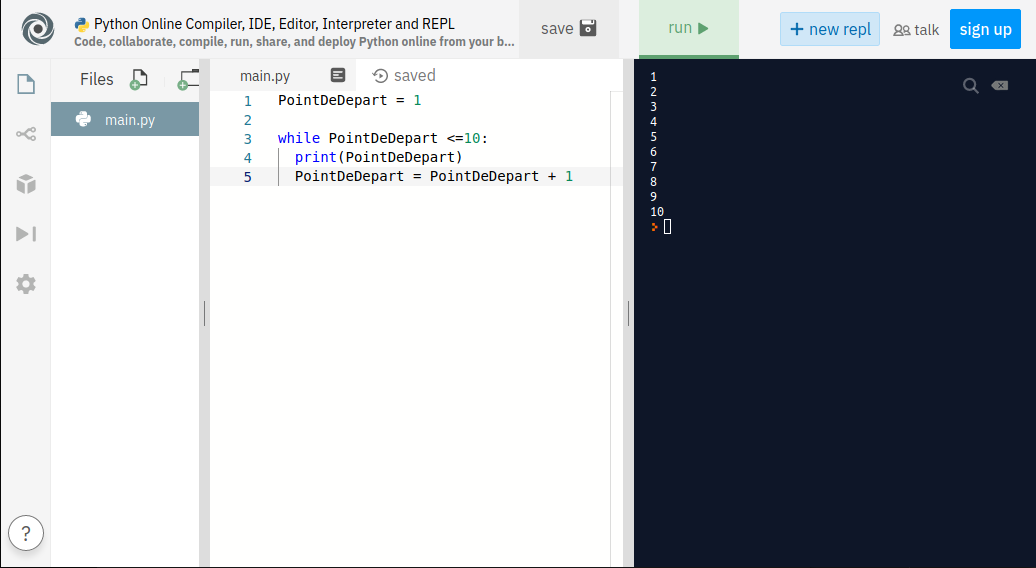
Youpi ! Je compte jusqu’a 10 !
Maintenant, je vais rajouter ce qu’il faut pour avoir l’URL complète.
baseURL = 'https://www.magic-ville.com/pics/big/futFR/' PointDeDepart = 1 while PointDeDepart <=10: newURL = baseURL + str(PointDeDepart) + '.jpg' print(newURL) PointDeDepart = PointDeDepart + 1
Voilà le résultat (oui WordPress c’est du caca, il voulait rien savoir je suis obligé d’intégrer le résultat comme une image)
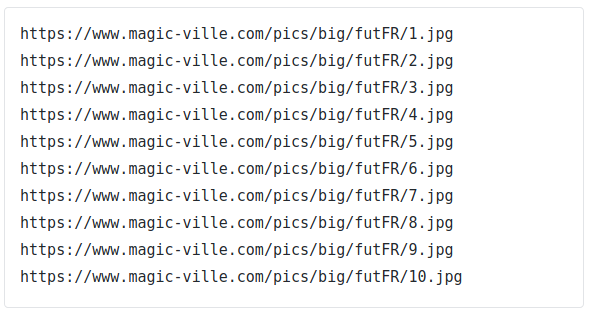
Alors on est content, mais je vous rappel que c’est pas 1.jpg mais 001. jpg !
Une petite recherche sur les internets, je tombe là dessus et on en arrive a ce bout de code là :
baseURL = 'https://www.magic-ville.com/pics/big/futFR/'
PointDeDepart = 1
while PointDeDepart <=10:
newURL = baseURL + str(f'{PointDeDepart:03}') + '.jpg'
print(newURL)
PointDeDepart = PointDeDepart + 1
Et voilà le résultat : (encore une image car pas moyen de juste vous mettre le texte, WordPress veut impérativement mettre des balises autour…)
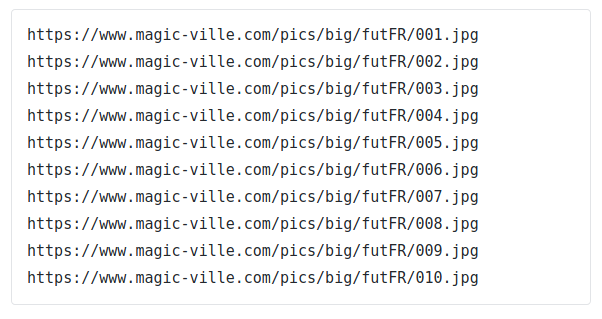
Youpi ! Cliquons sur un lien pour tester… Ça marche ! Maintenant téléchargeons les images…
Toujours en cherchant sur les internets, j’ai trouvé ça ! Ça tombe bien, c’est ce qu’on veut !
import urllib.request
baseURL = 'https://www.magic-ville.com/pics/big/futFR/'
PointDeDepart = 1
while PointDeDepart <=10:
newURL = baseURL + str(f'{PointDeDepart:03}') + '.jpg'
urllib.request.urlretrieve(newURL, str(f'{PointDeDepart:03}') + '.jpg')
PointDeDepart = PointDeDepart + 1
Voilà le résultat ! On voit qu’on a téléchargé les 10 premières images !
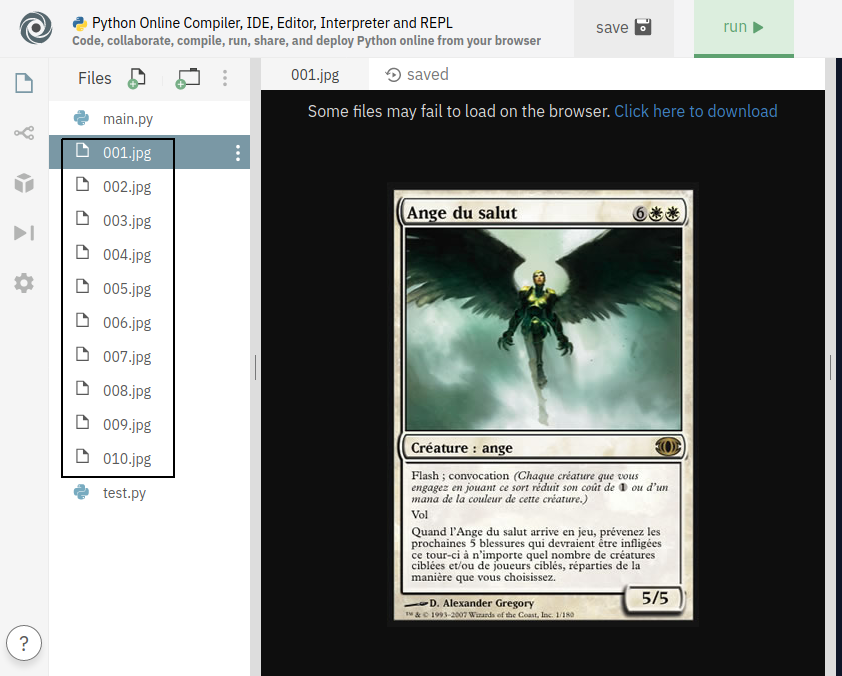
Alors évidemment, sur un environnement en ligne, c’est pas pratique mais voilà ce que ça donne si on exécute le code sur sa machine !
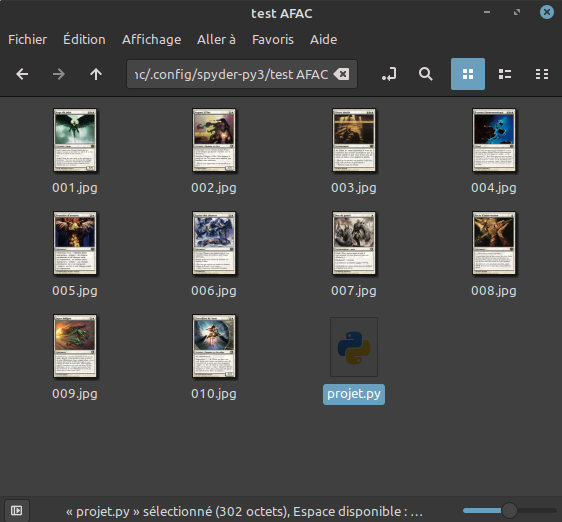
Youpi !
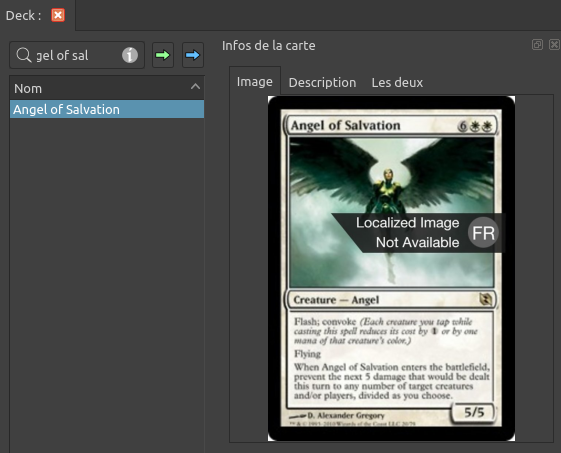
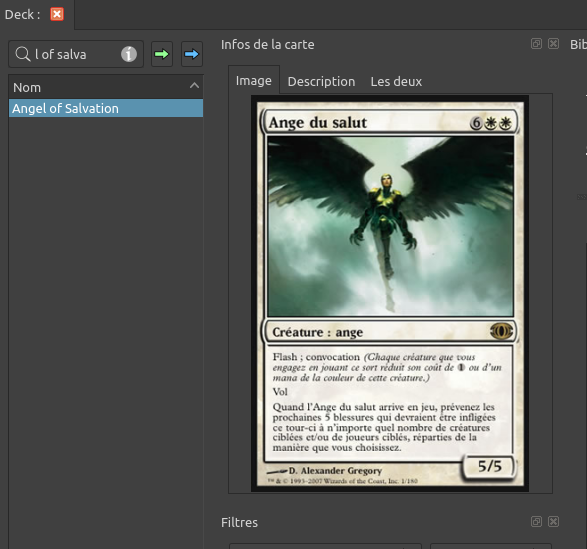
Est ce qu’on a fait tout ça pour rien ? Ben allons voir. Prenons le fichier 001.jpg : l’Ange de salut qu’on a vu ci dessus. Puis dans Cockatrice, faisons une recherche avec son nom anglais, Angel Of Salvation, on voit que l’image n’a pas été trouvé en français par Scryfall.
Retournons maintenant dans le répertoire des images de Cockatrice. Dans le répertoire downloadedPics ; on va ensuite chercher le dossier FUT ou le créer si il n’existe pas. Puis on va ajouter la carte qu’on vient de télécharger. On oublie pas de la renommer avec le bon nom !
Redémarrons Cockatrice pour prendre en compte ces modifications… Horreur ! Ça n’a pas marché… Pourquoi ? J’ai découvert lors de mes parties que Cockatrice va utiliser l’illustration la plus récente. Or, si on regarde bien ; dans Cockatrice, l’Ange de Salvation n’est pas celui de l’édition FUT (Futur Sight) mais d’une autre édition, à savoir Dual Deck : Elspeth VS Tezzeret.

Bon, du coup, on retourne dans le répertoire des images et on cherche le répertoire de notre extension… Pour information le trigramme est DDF. On remplace l’image existante par la notre, on fait bien attention au nom de la carte encore une fois. On relance Cockatrice. Et là : MIRACLE ! Ca fonctionne !
Demi-défaite
Alors certe ca marche. Mais on se rend compte d’un gros probléme que je n’avais pas identifié plus tôt : la gestion des extensions. Ca veut dire que pour chaque carte il faudra vérifier ces histoires d’extensions, remplacer la carte dans l’extension la plus récente etc… Ca serait tellement plus simple si tout était dans un seul répertoire !
Mais attendez une seconde… Tout à l’heure, on avait vu qu’il y avait DEUX répertoires pour gérer les images :
- CUSTOM
- downloadedPics
Il se passe quoi si je met ma carte dans CUSTOM ? Pour vérifier ça, je barbouille l’image pour m’en servir comme détrompeur. Ainsi, je verrai ce que Cockatrice charge comme illustration ! On relance Cockatrice pour mettre tout ça à jour et…
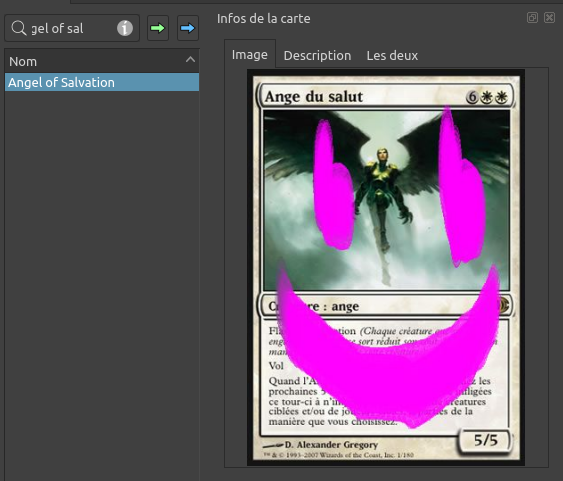
Tadaaa ! On a réussit ! On a donc plus à s’embêter avec les extensions ! On récupère les images, et on les mets là dedans !
La remontada !
Il subsiste encore un petit problème là dedans : comment on va faire pour renommer les cartes avec le bon nom ? On va pas s’amuser à le faire à la main pour chaque carte ! Pour ça, j’ai pour idée d’aller extraire le nom de la carte depuis le site MagicVille.
Reprenons l’Ange du Salut dans l’édition Future Sight ; puis examinons une nouvelle fois le code HTML de la page. On remarque que le nom de la carte est comprise entre deux balises très particulière :
<div class=S16>Angel of Salvation</div>
On pourrait faire une recherche dans ce code HTML et extraire le nom de la carte ? Elle est repéré par cette balise S16 ! Et bonne nouvelle, si on examine en détail le code de la page, il n’y a que deux occurrences ! Une pour le nom en Français, une autre pour le nom en Anglais ! Du coup, ça limite grandement les recherches !
Note : pour examiner le code de la page , faite un clic droit sur celle ci et « Code source de la page » (Sur Firefox, on fait comme ça en tout cas… Vous pouvez tenter aussi de copier coller ceci dans votre barre d’adresse :
view-source:https://www.magic-ville.com/fr/carte?ref=fut001
Mais du coup, comment on va faire pour relier la carte 001 au nom Angel of Salvation ? C’est en effet un problème que je n’avais pas anticipé… Réchéflissons !
Regardons l’URL de notre carte :
https://www.magic-ville.com/fr/carte?ref=fut001 Vos yeux attentifs auront certainement remarqué la fin de cette URL… fut désigne l’extension et 001 le numéro de la carte.
Du coup, on pourrait a nouveau balayer chaque URL (on sait le faire, on l’a fait pour les images tout à l’heure) et sur chaque page web, identifier le nom dans le code HTML, et l’emplacement de l’image !
Yapluka
Alors évidemment, ça va changer notre stratégie et une bonne partie du code qu’on a fait va être modifié en profondeur. Mais ça fait partie du jeu ! Repartons de zéro et simplifions notre problème pour s’attaquer à un petit morceau à la fois : là, le but, est simplement de scanner le code HTML d’une page, et de simplement récupérer le nom. Je me suis aidé de ça.
import re
import requests
response = requests.get('https://www.magic-ville.com/fr/carte?ref=fut001')
Name = re.search(r'<div class=S16>(.+)</div>',response.text).group(1)
print (Name)
Et on aura comme réponse « Ange du Salut » … Comme je l’ai expliqué plus tôt, il y a deux balises S16, la première contient le nom en Français, et l’autre est en Anglais. Ici, la recherche s’arrête dés qu’elle trouve le premier résultat. Il faudrait trouver un moyen de lui dire de prendre le deuxième résultat… Je me suis aidé de ça. Voici le code que j’ai réussi à créé, je vous ai rajouté des commentaires en prime 🙂
import re
import requests
response = requests.get('https://www.magic-ville.com/fr/carte?ref=fut001')
##On recherche toutes les balises S16 et on récupére ce qu'il y a à l'intérieur
Name = re.findall(r'<div class=S16>(.+)</div>',response.text)
## Voici tous les résultats :
print (Name)
##Pour récupérer uniquement le second résultat : (Rappel, en informatique, le premier élement d'une liste est à la position 0)
print (Name[1])
Si on essaye ce code, on obtient les résultats suivants :
['Ange du salut ', 'Angel of Salvation'] Angel of Salvation
La première ligne c’est le résultat de toute la recherche, la deuxième : uniquement le nom qui nous intéresse !!
Retrouver l’image
Bon, maintenant qu’on a retrouvé le nom, il faut retrouver l’image ! Pour cela on va une nouvelle fois scanner le code HTML pour récupérer l’adresse de l’image. En analysant la page comme précédemment, voici le petit morceau que je recherche :
<img src=../pics/big/futFR/001.jpg></td></tr>Coup de chance, il n’apparaît qu’une seule fois dans la page ! Dans l’absolu on pourrait utiliser la commande search au lieu de la commande findall ; mais j’ai pas réussi… Du coup j’ai réussi à récupérer futFR/001.jpg . On recolle ce petit bout pour reconstituer l’URL complète et télécharger l’image. C’est super simple !
## import des librairies
import urllib.request
import re
import requests
## définition des variables
baseURL = 'https://www.magic-ville.com/pics/big/'
response = requests.get('https://www.magic-ville.com/fr/carte?ref=fut001')
##On recherche toutes les balises S16 et on récupére ce qu'il y a à l'intérieur
Name = re.findall(r'<div class=S16>(.+)</div>',response.text)
Image = re.findall(r'<img src=../pics/big/(.+)></td></tr>',response.text)
## reconsitution de l'URL de l'image et téléchargement
newURL = baseURL + str(Image[0])
## Nom de la carte en anglais , et de son URL pour vérifier...
print (Name[1])
print (newURL)
## téléchargement de la carte
urllib.request.urlretrieve(newURL, str(Name[1]))

A grande échelle
Et si maintenant, on téléchargeait TOUTES les cartes de l’extension FUT ? Il suffit de balayer chaque page du site ! Rappelez vous de l’URL :
https://www.magic-ville.com/fr/carte?ref=fut001 Il suffirait d’incrémenter les trois derniers chiffres, 001…002…003… jusque la dernière carte de l’extension (elle en contient 180) et on est bon ! Pour m’aider, j’ai repris tout ce qu’on a fait avant, et j’ai fusionné tout ça pour aboutir à ceci : (notez que j’en ai profité pour changer le nom des variables et continué de commenter le code)
## import des librairies
import urllib.request
import re
import requests
## définition des variables, on différencie l'url de l'image, de l'URL qui nous permettra de retrouver le nom
baseURL_img = 'https://www.magic-ville.com/pics/big/'
baseURL_name = 'https://www.magic-ville.com/fr/carte?ref=fut'
## on commence par la premiére carte, on arrête à la 180éme (la derniére)
start = 1
end = 180
## on fait une boucle, qui s'arrêtera à la derniére carte
while start <=end:
## on va générer l'URL de la page à scanner
newURL_name = baseURL_name +str(f'{start:03}')
## on récupére le code HTML de la page
codeHTML = requests.get(newURL_name)
## On recherche toutes les balises S16 et on récupére ce qu'il y a à l'intérieur (le nom de la carte)
Name = re.findall(r'<div class=S16>(.+)</div>',codeHTML.text)
Image = re.findall(r'<img src=../pics/big/(.+)></td></tr>',codeHTML.text)
## On génére de l'URL de l'image
newURL_img = baseURL_img + str(Image[0])
## On télécharge la carte
urllib.request.urlretrieve(newURL_img, str(Name[1]+'.jpg'))
## On affiche ce qui se passe à l'écran et le nombre de carte restante
print ('Téléchargement de', str(Name[1]), str(start),'/',str(end))
## On incrémente start
start = start + 1
Voilà ce que ça donne en image ! (Excusez moi de la qualité, j’ai fait au mieux… On peut pas importer des formats vidéos sur wordpress.com… 🙁 )
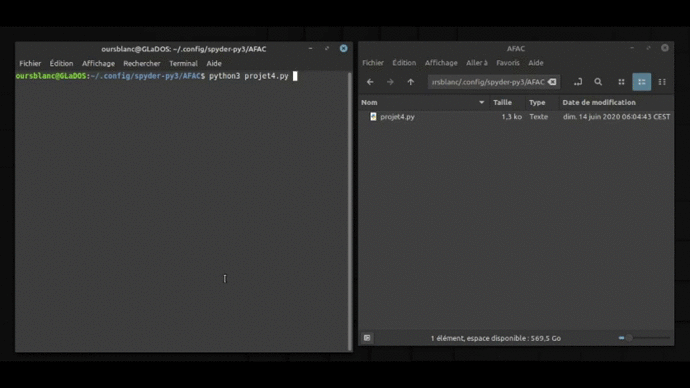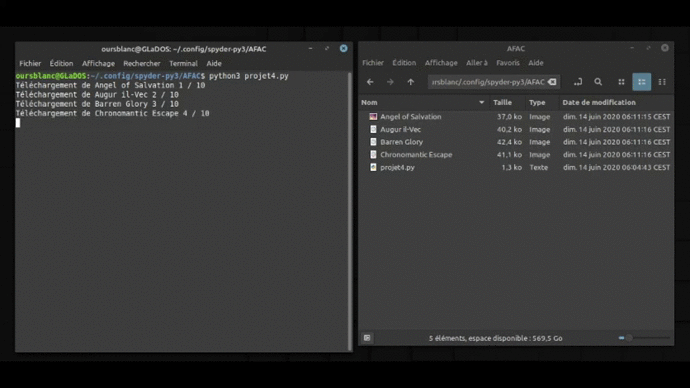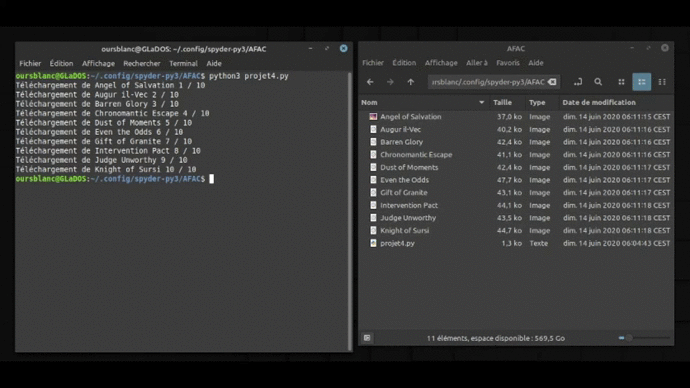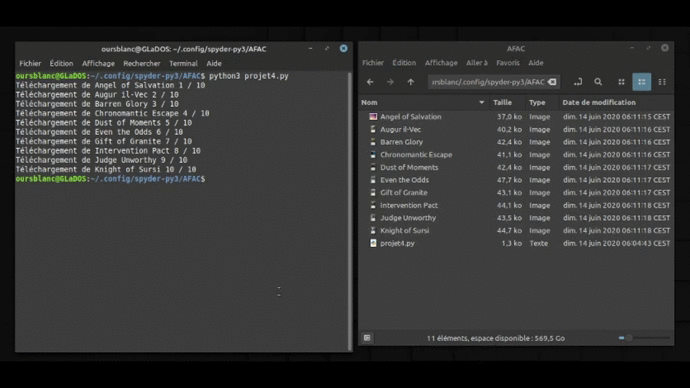
Améliorer le machin
Les cartes en Français uniquement !
Bon alors, on est content. Qu’est ce qu’on pourrait faire pour améliorer le machin ? Entre autre, on pourrait ne télécharger la carte QUE si elle est en français. Je rappel que sur MagicVille, les cartes de l’extension Mirrodin sont en anglais (c’est un exemple parmi tant d’autres). Tout à l’heure, on a vu que les URL des scans en français ont la mention FR juste après le trigramme de l’extension. Voici un exemple :
https://www.magic-ville.com/pics/big/futFR/001.jpgRetirer le FR et vous aurez la carte en anglais ! On pourrait faire en sorte que notre petit bout de code vérifie que ce petit FR est présent avant de télécharger la carte… Alors je me suis aidé de ça, et de ça. J’en ai profité pour faire un truc un peu plus joli sur l’affichage des résultats. J’ai donc ajouté le trigramme mrd pour Mirrodin, et avoir mis la fin à 10 pour ne tester qu’avec les dix premières cartes.
## import des librairies
import urllib.request
import re
import requests
## définition des variables, on différencie l'url de l'image, de l'URL qui nous permettra de retrouver le nom
baseURL_img = 'https://www.magic-ville.com/pics/big/'
baseURL_name = 'https://www.magic-ville.com/fr/carte?ref=mrd'
## on commence par la premiére carte, on arrête à la 180éme (la derniére)
start = 1
end = 10
## on fait une boucle, qui s'arrêtera à la derniére carte
while start <=end:
## on va générer l'URL de la page à scanner
newURL_name = baseURL_name +str(f'{start:03}')
## on récupére le code HTML de la page
codeHTML = requests.get(newURL_name)
## On recherche toutes les balises S16 et on récupére ce qu'il y a à l'intérieur (le nom de la carte)
Name = re.findall(r'<div class=S16>(.+)</div>',codeHTML.text)
Image = re.findall(r'<img src=../pics/big/(.+)></td></tr>',codeHTML.text)
if "FR" in str(Image):
## On génére de l'URL de l'image
newURL_img = baseURL_img + str(Image[0])
## On télécharge la carte
urllib.request.urlretrieve(newURL_img, str(Name[1])+'.jpg')
## On affiche ce qui se passe à l'écran et le nombre de carte restante
print ('[',str(start),'/',str(end),'] - Téléchargement de', str(Name[1]))
else:
print ('[',str(start),'/',str(end),'] - Pas de scan en français - ', str(Name[1]) )
## On incrémente start
start = start + 1
Voilà ce qu’on obtient comme résultat avec les 10 premières cartes de Mirrodin :
[ 1 / 10 ] - Pas de scan en français - Altar's Light
[ 2 / 10 ] - Pas de scan en français - Arrest
[ 3 / 10 ] - Pas de scan en français - Auriok Bladewarden
[ 4 / 10 ] - Pas de scan en français - Auriok Steelshaper
[ 5 / 10 ] - Pas de scan en français - Auriok Transfixer
[ 6 / 10 ] - Pas de scan en français - Awe Strike
[ 7 / 10 ] - Pas de scan en français - Blinding Beam
[ 8 / 10 ] - Pas de scan en français - Leonin Abunas
[ 9 / 10 ] - Pas de scan en français - Leonin Den-Guard
[ 10 / 10 ] - Pas de scan en français - Leonin ElderDéterminer tout seul la fin de l’extension
Depuis tout à l’heure on s’amuse à rentrer à la main combien de carte vont être balayé. Sauf que dans Magic, les éditions ne comportent pas toutes le même nombre de cartes. A la louche ça va de 100 à 400 cartes selon les éditions. Du coup, plutôt que de s’embêter à modifier ça à la main, on pourra faire en sorte que notre petit programme s’arrête tout seul une fois qu’il a fini.
J’ai aucune idée de comment faire ça, alors j’ai fait exprés de faire planter le programme. J’ai demandé de balayer les cartes 179 à 190 de l’extension fut . L’extension ne comporte que 180 cartes. Voyons voir ce qu’il se passe :
[ 179 / 190 ] - Téléchargement de River of Tears
[ 180 / 190 ] - Téléchargement de Zoetic Cavern
Traceback (most recent call last):
File "projet4.py", line 38, in <module>
print ('[',str(start),'/',str(end),'] - Pas de scan en français - ', str(Name[1]) )
IndexError: list index out of rangeTout va bien sur les deux premières cartes, et puis… patatra ! On pourrait se servir de cette erreur pour arrêter le tout proprement ? Je me suis aidé de ça.
## import des librairies
import urllib.request
import re
import requests
## définition des variables, on différencie l'url de l'image, de l'URL qui nous permettra de retrouver le nom
baseURL_img = 'https://www.magic-ville.com/pics/big/'
baseURL_name = 'https://www.magic-ville.com/fr/carte?ref=mrd'
## on commence par la premiére carte, on arrête à la 180éme (la derniére)
start = 1
## on fait une boucle qui s'arrêtera tout seul à la derniére carte de l'extension
while start >=1:
## on va générer l'URL de la page à scanner
newURL_name = baseURL_name +str(f'{start:03}')
## on récupére le code HTML de la page
codeHTML = requests.get(newURL_name)
## On recherche toutes les balises S16 et on récupére ce qu'il y a à l'intérieur (le nom de la carte)
Name = re.findall(r'<div class=S16>(.+)</div>',codeHTML.text)
Image = re.findall(r'<img src=../pics/big/(.+)></td></tr>',codeHTML.text)
if "FR" in str(Image):
## On génére de l'URL de l'image
newURL_img = baseURL_img + str(Image[0])
## On télécharge la carte
urllib.request.urlretrieve(newURL_img, str(Name[1])+'.jpg')
## On affiche ce qui se passe à l'écran et le nombre de carte restante
## en cas d'erreur, c'est que c'est fini !
try:
print ('[',str(start),'] - Téléchargement de', str(Name[1]))
except IndexError:
break
else:
try:
print ('[',str(start),'] - Pas de scan en français - ', str(Name[1]) )
except IndexError:
break
## On incrémente start
start = start + 1
print('Extraction terminée')
Voilà le résultat qu’on obtient (y’a que la fin hein !)
[ 300 ] - Pas de scan en français - Mountain
[ 301 ] - Pas de scan en français - Mountain
[ 302 ] - Pas de scan en français - Mountain
[ 303 ] - Pas de scan en français - Forest
[ 304 ] - Pas de scan en français - Forest
[ 305 ] - Pas de scan en français - Forest
[ 306 ] - Pas de scan en français - Forest
Extraction terminéeVoilà, donc le code s’arrête tout seul au lieu d’afficher une erreur. Pas mal hein ?
Éviter de télécharger une carte si on l’a déjà
Pour améliorer encore mon petit bout de programme et accéler son éxecution, on peut vérifier si l’on a une carte ou non avant de la télécharger. Bon alors pour ça, j’ai tout simplement rajouté une condition en m’aidant de ça et de ça.
## import des librairies
import urllib.request
import re
import requests
import os.path
## définition des variables, on différencie l'url de l'image, de l'URL qui nous permettra de retrouver le nom
baseURL_img = 'https://www.magic-ville.com/pics/big/'
baseURL_name = 'https://www.magic-ville.com/fr/carte?ref=fut'
## on commence par la premiére carte, on arrête à la 180éme (la derniére)
start = 1
## on fait une boucle qui s'arrêtera tout seul à la derniére carte de l'extension
while start >=1:
## on va générer l'URL de la page à scanner
newURL_name = baseURL_name +str(f'{start:03}')
## on récupére le code HTML de la page
codeHTML = requests.get(newURL_name)
## On recherche toutes les balises S16 et on récupére ce qu'il y a à l'intérieur (le nom de la carte)
Name = re.findall(r'<div class=S16>(.+)</div>',codeHTML.text)
Image = re.findall(r'<img src=../pics/big/(.+)></td></tr>',codeHTML.text)
## Si le fichier n'existe pas, alors on va télécharger la carte
if not os.path.isfile(str(Name[1]+'.jpg')):
if "FR" in str(Image):
## On génére de l'URL de l'image
newURL_img = baseURL_img + str(Image[0])
## On télécharge la carte
urllib.request.urlretrieve(newURL_img, str(Name[1])+'.jpg')
## On affiche ce qui se passe à l'écran et le nombre de carte restante
try:
print ('[',str(start),'] - Téléchargement de', str(Name[1]))
except IndexError:
break
else:
try:
print ('[',str(start),'] - Pas de scan en français - ', str(Name[1]) )
except IndexError:
break
else:
print ('[',str(start),'] - La carte existe déja - ', str(Name[1]) )
## On incrémente start
start = start + 1
print('Extraction terminée')
Voici un petit extrait de ce que l’on obtiendrait si on avait des doublons :
[ 19 ] - La carte existe déja - Blade of the Sixth Pride
[ 20 ] - La carte existe déja - Bound in Silence
[ 21 ] - La carte existe déja - Daybreak Coronet
[ 22 ] - La carte existe déja - Goldmeadow Lookout
[ 23 ] - Téléchargement de Imperial Mask
[ 24 ] - Téléchargement de Lucent Liminid
[ 25 ] - Téléchargement de Lumithread Field
[ 26 ] - Téléchargement de Lymph SliverVoici un petit extrait de ce que ca pourrait donner :
[ 19 ] - La carte existe déja - Blade of the Sixth Pride
[ 20 ] - La carte existe déja - Bound in Silence
[ 21 ] - La carte existe déja - Daybreak Coronet
[ 22 ] - La carte existe déja - Goldmeadow Lookout
[ 23 ] - Téléchargement de Imperial Mask
[ 24 ] - Téléchargement de Lucent Liminid
[ 25 ] - Téléchargement de Lumithread Field
[ 26 ] - Téléchargement de Lymph SliverNe télécharger la carte que si elle n’est pas disponnible en francais sur Scryfall.
Bon alors on a presque tout optimisé. Voilà le dernier point . J’ai réfléchis. J’ai pas trouvé. En effet sur le site de Scryfall , rien n’indique si l’illustration est en Français ou en Anglais si ce n’est : l’image elle même. Alors a moins de s’amuser a faire de la reconnaissance automatique sur les images ; je vois pas comment on pourrait s’y prendre. Et puis, ca serait une solution un peu de bourrin : c’est tuer des mouches à la catapulte…
Et maintenant ?
Alors voilà, j’ai rempli mon objectif en a peine quelques heures… (Sachant que je codais, et qu’en même temps je rédigeais l’article, tout en prenant des captures d’écrans…)
Est ce qu’on pourrait pas aller plus loin et télécharger toutes les cartes en Francais de toutes les extensions ? Bon alors allons y !
Trouver la liste de toutes les extensions.
On l’a vu, les cartes sont rangés par extension et chaque extension est défini avec un trigramme. On avait vu que :
- FUT pour Future Sight
- MRD pour Mirrodin
- etc…
L’idée serait donc d’avoir la liste de tous les trigrammes et ainsi pouvoir balayer toutes les éditions sur le site de MagicVille !
Il existe une telle liste, plus ou moins officielle, que l’on retrouve sur Scryfall. Seulement voilà, ca aurait été trop simple. Il s’avére que MagicVille n’utilise parfois pas les mêmes abréviations que Scryfall. Un exemple parmis tant d’autres : Lorwynn a pour trigramme LRW chez Scryfall, et LOR chez MagicVille. Du coup, je vais m’amuser à trier et à vérifier pour chaque trigramme si il est correct ou non.
Générer la liste des extensions
Bon, maintenant qu’on sait se débrouiller avec du python, peut être qu’on pourrait générer cette liste à partir du site MagicVille ? J’ai pas mal cherché et j’ai finis par trouver (avec l’aide de mon ami Stef). En effet, le site MagicVille dispose d’une page pour faire des recherches avancées. Et c’est en examinant le code contenu sur cette page que j’ai trouvé la perle rare !
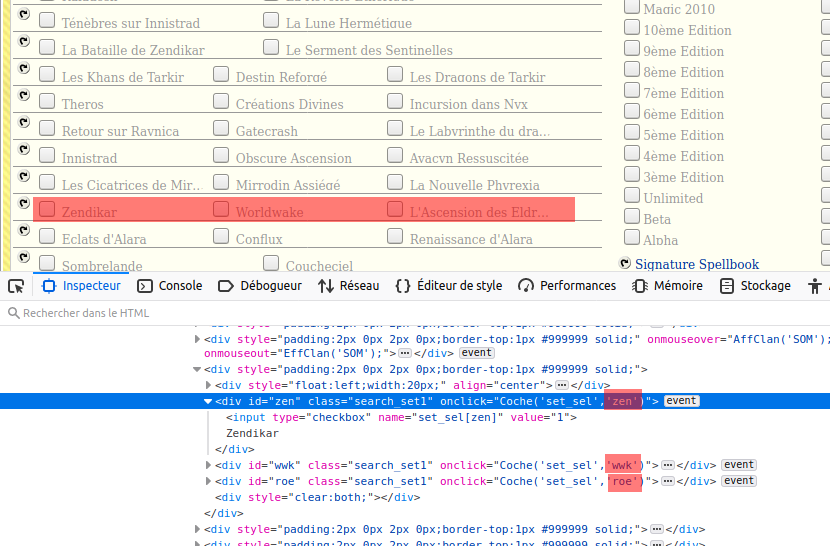
En effet, on voit dans cet exemple que chaque case à cocher est relié à une propriété, et à chaque fois on retrouve le trigramme !
- zen pour Zendikar
- wwk pour Worldwake
- roe pour L’Ascencion des Eldrazi (Rise Of Eldrazi)
On peut appliquer ça à toutes les autres extensions : vous avez compris le principe ! Avec l’aide de ce site j’ai créé ce tout petit bout de code :
import re
import requests
extHTML = requests.get('https://magic-ville.fr/fr/rech_avancee')
##On recherche tous les trigrammes
EXT = re.findall('name=set_sel\[(.*?)\]', extHTML.text)
## Voici tous les résultats :
print (EXT)
Qui nous donne ce résultat là :
['iko', 'thb', 'eld', 'grn', 'rna', 'war', 'dom', 'xln', 'rix', 'akh', 'hou', 'kld', 'aer', 'soi', 'emn', 'bfz', 'ogw', 'ktk', 'frf', 'dtk', 'ths', 'bng', 'jou', 'rtr', 'gtc', 'dgm', 'isd', 'dka', 'avr', 'som', 'mbs', 'nph', 'zen', 'wwk', 'roe', 'soa', 'con', 'alr', 'sha', 'eve', 'lor', 'mor', 'tsp', 'plc', 'fut', 'rav', 'gui', 'dis', 'chk', 'bek', 'sak', 'mrd', 'drs', 'fda', 'ons', 'lgi', 'sco', 'ody', 'tor', 'jud', 'inv', 'pla', 'apo', 'mer', 'nem', 'pro', 'urs', 'url', 'urd', 'tem', 'str', 'exo', 'mir', 'vis', 'wea', 'ice', 'all', 'col', 'm21', 'm20', 'm19', 'ori', '15m', '14m', '13m', '12m', '11m', '10m', 'xth', '9th', '8th', '7th', '6th', '5th', '4th', 'rev', 'abu', 'bet', 'alp', 'ss3', 'ss2', 'ss1', 'gs1', 'my3', 'my2', 'uma', 'myt', 'aki', 'kli', 'zex', 'eur', 'gur', 'apa', 'gra', 'fir', 'sli', 'und', 'ust', 'unh', 'ung', '2un', '2xm', 'q04', 'q03', 'myb', 'sld', 'q02', 'gk2', 'ulm', 'gk1', 'q01', '25m', 'ima', 'and', '17w', 'mmc', 'pad', 'ema', '16w', 'mmb', 'med', 'mma', '2pd', 'ard', 'dop', 'pcd', 'cst', 'dec', 'bea', 'bro', 'ath', 'i2p', 'chr', 'ren', 'sum', 'evi', 'mvg', 'mvm', 'nvo', 'bvc', 'zve', 'evk', 'dda', 'svc', 'jvv', 'hvm', 'svt', 'ivg', 'vvk', 'avn', 'kvd', 'evt', 'pvc', 'gvl', 'dvd', 'jvc', 'evg', 'jmp', 'c20', 'gn2', 'c19', 'mh1', 'gnt', 'c18', 'bbd', 'cm2', 'eoi', '17c', 'anb', 'can', 'pca', '16c', '2cn', '15c', '14c', 'cns', 'joc', 'bnc', 'thc', '13c', 'cma', '2pc', 'arc', 'pch', 'cmd', 'van', 'fnm', 'pre', 'pmo', 'dci', 'gat', 'rew', 'mpt', 'jss', 'are', 'aaa', 'uni', 'vir', 'ha3', 'ha2', 'ha1', 'ana', 'tpr', 'vma', '4me', '3me', '2me', '1me', 'hom', 'fal', 'dar', 'leg', 'ant', 'ara', 's2k', 'sta', 'ptk', 'psa', 'por', 'ftr', 'fvo', 'fva', 'anh', 'fvt', 'fre', 'fvl', 'fvr', 'fve', 'fvd']Il ne nous reste plus qu’a intégré ce petit bout de code dans le précédent, et on aura tout bon !
Fuuuuuuuusion !
Je me suis aidé de ça ainsi de tout ce qu’on a vu avant. J’ai modifié un peu le code notamment au niveau des break. Car cette fois ci, une fois qu’on a fini de scanner la premiére extension, on passe à la suivante ! Or on avait juste fait un systeme pour quitter le programme . C’est pas ce qu’on veut. En bricolant je suis donc arrivé à ça :
## Programme en Python permettant de récupérer les scans des cartes Magic en Francais depuis le site MagicVille
## import des librairies
import urllib.request
import re
import requests
import os.path
## définition des variables, on différencie l'url de l'image, de l'URL qui nous permettra de retrouver le nom
baseURL_img = 'https://www.magic-ville.com/pics/big/'
baseURL_name = 'https://www.magic-ville.com/fr/carte?ref='
## On récupére le code HTML de la page contenant toutes les extensions
extHTML = requests.get('https://magic-ville.fr/fr/rech_avancee')
## On récupére uniquement la liste de toutes les extensions (trigrammes)
EXT_list = re.findall('name=set_sel\[(.*?)\]', extHTML.text)
## Pour chaque extension dans la liste
for i in EXT_list:
EXT_name = i
## on commence par la premiére carte
start = 1
fin = 0
## on fait une boucle qui s'arrêtera tout seul à la derniére carte de l'extension
while fin == 0:
## on va générer l'URL de la page à scanner
newURL_name = baseURL_name + i +str(f'{start:03}')
## on récupére le code HTML de la page
codeHTML = requests.get(newURL_name)
## Dans ce code, on recherche le nom de la carte, et son image.
try :
Name = re.findall(r'<div class=S16>(.+)</div>',codeHTML.text)
except IndexError:
pass
try :
Image = re.findall(r'<img src=../pics/big/(.+)></td></tr>',codeHTML.text)
except :
pass
## On vérifie que l'on est pas arrivé à la fin de l'extension
try:
print(Name[1])
except IndexError:
fin = 1
pass
else:
## Si on ne posséde pas déja ce fichier, alors on va télécharger la carte
if not os.path.isfile(str(Name[1]+'.jpg')):
if "FR" in str(Image):
## On génére de l'URL de l'image
newURL_img = baseURL_img + str(Image[0])
## On télécharge la carte
try:
urllib.request.urlretrieve(newURL_img, str(Name[1])+'.jpg')
except:
pass
## Message
print ('[',str(start),'-',str(i),'] - Téléchargement du scan')
else:
## Message
print ('[',str(start),'-',str(i),'] - Pas de scan en français - ')
else:
## Message
print ('[',str(start),'-',str(i),'] - Le scan existe déja - ')
## On incrémente start
start = start + 1
print('Extraction terminée')
J’ai eu quelques petites problémes, notamment avec des cartes comme celle ci.
Comme vous le voyez, il n’y a pas deux balises S16 sur cette page mais 4 ! Du coup, lorsqu’on demande de prendre le nom de la deuxiéme balise on prend Démonstration de combat au lieu de Embereth Shieldbreaker
Encore un truc qu’on pourrait améliorer …Mais j’en ai déja assez fait ! Evidemment je ne garanti pas du résultat, j’ai parfois des erreurs qui font tout planter… Pour éviter ça , j’ai mis des « pass » un peu partout pour ignorer les erreurs… Tant pis si on perd quelques cartes en route…
Conclusion et liens de téléchargement
Bon ben j’ai réussi ! J’ai lancé le script et il a mis environ 3h30 pour télécharger environ 12.000 images (~500 mo) … C’est long, il faudra optimiser ça à l’occasion.
Le .py
D’autre part : voici le lien pour télécharger le fichier .py et vous amuser avec. Faites attention à pas trop envoyer de requête sur le site pour éviter les problémes !





1 Pingback